이전글 : (논문리뷰) Fast R-CNN 설명 및 정리
Fast R-CNN 설명 및 정리
이전글 : Object Detection, R-CNN 설명 및 정리 Object Detection, R-CNN 설명 및 정리 컴퓨터비전에서의 문제들은 크게 다음 4가지로 분류할 수 있다. 1. Classification 2. Object Detection 3. Image Segmenta..
ganghee-lee.tistory.com
<Introduction>
R-CNN에서는 3가지 모듈 (region proposal, classification, bounding box regression)을 각각 따로따로 수행한다.
(1)region proposal 추출 → 각 region proposal별로 CNN 연산 → (2)classification, (3)bounding box regression
Fast R-CNN에서는 region proposal을 CNN level로 통과시켜 classification, bounding box regression을 하나로 묶었다.
(1)region proposal 추출 → 전체 image CNN 연산 → RoI projection, RoI Pooling
→ (2)classification, bounding box regression
그러나 여전히 region proposal인 Selective search알고리즘을 CNN외부에서 연산하므로 RoI 생성단계가 병목이다.
따라서 Faster R-CNN에서는 detection에서 쓰인 conv feature을 RPN에서도 공유해서
RoI생성역시 CNN level에서 수행하여 속도를 향상시킨다.
"Region Proposal도 Selective search 쓰지말고 CNN - (classification | bounding box regression)
이 네트워크 안에서 같이 해보자!"
<Faster R-CNN>
Selective search가 느린이유는 cpu에서 돌기 때문이다.
따라서 Region proposal 생성하는 네트워크도 gpu에 넣기 위해서 Conv layer에서 생성하도록 하자는게 아이디어이다.
Faster R-CNN은 한마디로 RPN + Fast R-CNN이라할 수 있다.
Faster R-CNN은 Fast R-CNN구조에서 conv feature map과 RoI Pooling사이에 RoI를 생성하는
Region Proposal Network가 추가된 구조이다.

그리고 Faster R-CNN에서는 RPN 네트워크에서 사용할 CNN과
Fast R-CNN에서 classification, bbox regression을 위해 사용한 CNN 네트워크를 공유하자는 개념에서 나왔다.

결국 위 그림에서와 같이 CNN을 통과하여 생성된 conv feature map이 RPN에 의해 RoI를 생성한다.
주의해야할 것이 생성된 RoI는 feature map에서의 RoI가 아닌 original image에서의 RoI이다.
(그래서 코드 상에서도 anchor box의 scale은 original image 크기에 맞춰서 (128, 256, 512)와 같이 생성하고
이 anchor box와 network의 output 값 사이의 loss를 optimize하도록 훈련시킨다.)
따라서 original image위에서 생성된 RoI는 아래 그림과 같이 conv feature map의 크기에 맞게 rescaling된다.

이렇게 feature map에 RoI가 투영되고 나면 FC layer에 의해 classification과 bbox regression이 수행된다.

위 그림에서 보다시피 마지막에 FC layer를 사용하기에 input size를 맞춰주기 위해 RoI pooling을 사용한다.
RoI pooling을 사용하니까 RoI들의 size가 달라도 되는것처럼 original image의 input size도 달라도된다.
그러나 구현할때 코드를 보면 original image의 size는 같은 크기로 맞춰주는데 그 이유는
"vgg의 경우 244x224, resNet의 경우 min : 600, max : 1024 등.. 으로 맞춰줄때 성능이 가장 좋기 때문이다"
original image를 resize할때 손실되는 data가 존재하듯이
feature map을 RoI pooling에서 max pooling을 통해 resize할때 손실되는 data 역시 존재한다.
따라서 이때 손실되는 data와 input image 자체를 resize할때 손실되는 data 사이의 Trade off가 각각
vgg의 경우 224x224, resNet은 600~1024이기에 input size를 고정시킨 것이다.
"따라서 요즘에는 이 FC layer 대신 GAP(Global Average Pooling)을 사용하는 추세이다"
GAP를 사용하면 input size와 관계없이 1 value로 average pooling하기에 filter의 개수만 고정되어있으면 되기 때문이다.
따라서 input size를 고정시킬 필요없기에 RoI pooling으로 인해 손실되는 data역시 없어서 original image의 size역시
고정시킬 필요가 없는 장점이 있다.
더욱 자세한 이야기는 따로 게시글로 다루도록 하겠다.
GAP(Global Average Pooling) vs FCN(Fully Convolutional Network)
GAP(Global Average Pooling) vs FCN(Fully Convolutional Network)
Fully convolutional network란 1x1 convolution layer을 말한다. 일반적으로 Classification에서 Conv-Pool layer를 통과한 후 마지막에 Fully Connected Layer를 거쳐 softmax함수로 classification이 진..
ganghee-lee.tistory.com
그럼먼저 RPN 네트워크에 대해서 살펴보자
<RPN (Region Proposal Network)>

RPN의 input 값은 이전 CNN 모델에서 뽑아낸 feature map이다.
Region proposal을 생성하기 위해 feature map위에 nxn window를 sliding window시킨다.
이때, object의 크기와 비율이 어떻게 될지모르므로 k개의 anchor box를 미리 정의해놓는다.
이 anchor box가 bounding box가 될 수 있는 것이고 미리 가능할만한 box모양 k개를 정의해놓는 것이다.
여기서는 가로세로길이 3종류 x 비율 3종류 = 9개의 anchor box를 이용한다.
이 단계에서 9개의 anchor box를 이용하여 classification과 bbox regression을 먼저 구한다. (For 학습)
먼저, CNN에서 뽑아낸 feature map에 대해 3x3 conv filter 256개를 연산하여 depth를 256으로 만든다.
그 후 1x1 conv 두개를 이용하여 각각 classification과 bbox regression을 계산한다.
* 1x1 convolution 이란?
input 차원이 nxnx4라고 할때 1x1 convolution 2개를 이용하면 결국 input nxn짜리 4개에 대해
convolution 2개랑 아래와 같은 연산을 하는 것이다.
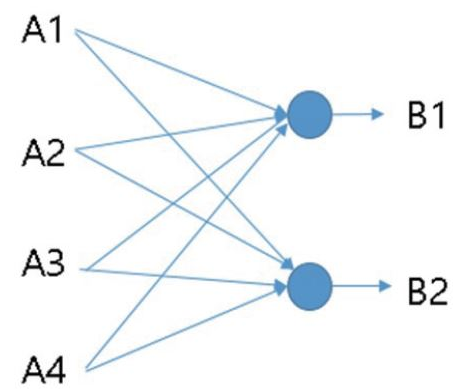
따라서 1x1 convolution은 fully connected layer와 같다고 한다.
다시 돌아와서 RPN에서 이렇게 1x1 convolution을 이용하여 classification과 bbox regression을 계산하는데
이때 네트워크를 가볍게 만들기 위해 binary classification으로 bbox에 물체가 있나 없나만 판단한다.
무슨 물체인지 classification하는 것은 마지막 classification 단계에서 한다.
RPN단계에서 classification과 bbox regression을 하는 이유는 결국 학습을 위함이다.
위 단계로부터 positive / negative examples들을 뽑아내는데 다음 기준에 따른다.
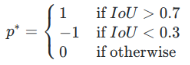
IoU가 0.7보다 크거나, 한 지점에서 모든 anchor box중 가장 IoU가 큰 anchor box는 positive example로 만든다.
IoU가 0.3보다 작으면 object가 아닌 background를 뜻하므로 negative example로 만들고
이 사이에 있는 IoU에 대해서는 애매한 값이므로 학습 데이터로 이용하지 않는다.
<Non-Maximu Suppression>
Faster R-CNN에 대한 학습이 완료된 후 RPN모델을 예측시키며 하마 한 객체당 여러 proposal값이 나올 것이다.
이 문제를 해결하기 위해 NMS알고리즘을 사용하여 proposal의 개수를 줄인다.
NMS알고리즘은 다음과 같다.
1. box들의 score(confidence)를 기준으로 정렬한다.
2. score가 가장 높은 box부터 시작해서 다른 모든 box들과 IoU를 계산해서 0.7이상이면 같은 객체를 detect한 box라고
생각할 수 있기 때문에 해당 box는 지운다.
3. 최종적으로 각 object별로 score가 가장 높은 box 하나씩만 남게 된다.


학습과정

<Bounding box regression>


<Loss Function>
최종 Loss = (Classification Loss + Regression Loss)

Bounding box regression Loss
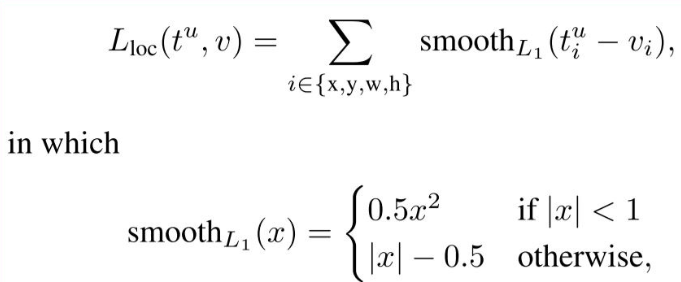
이상으로 Faster R-CNN 논문에 대한 리뷰를 마쳤습니다.
해당 논문의 재구현 혹은 자세한 코드를 보고싶다면 아래 링크에서 확인하실 수 있습니다.
https://github.com/Kanghee-Lee/Faster-RCNN_TF-RPN-
Kanghee-Lee/Faster-RCNN_TF-RPN-
Region proposal network of Faster-RCNN with Tensorflow - Kanghee-Lee/Faster-RCNN_TF-RPN-
github.com
코랩을 통해서 구현하였으며 쉽게 이해할 수 있도록 최대한 자세하게 line-by-line으로 주석달아 설명하고 있습니다.
Faster R-CNN의 Region Proposal Network를 구현하였습니다.
혹시나 이해가 안되는 부분이나 틀린 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
다음글 : (논문리뷰) Mask R-CNN 설명 및 정리
Mask R-CNN 설명 및 정리
이전글 : Faster R-CNN 설명 및 정리 Faster R-CNN 설명 및 정리 이전글 : Fast R-CNN 설명 및 정리 Fast R-CNN 설명 및 정리 이전글 : Object Detection, R-CNN 설명 및 정리 Object Detection, R-CNN 설명 및 정..
ganghee-lee.tistory.com
'인공지능 AI > 논문리뷰 and 재구현' 카테고리의 다른 글
| (논문리뷰&재구현) YOLACT 설명 및 정리 - (1) (4) | 2020.02.16 |
|---|---|
| (논문리뷰) ResNet 설명 및 정리 (8) | 2020.02.08 |
| (논문리뷰&재구현) Mask R-CNN 설명 및 정리 (17) | 2020.02.08 |
| (논문리뷰) Fast R-CNN 설명 및 정리 (4) | 2020.01.14 |
| (논문리뷰) R-CNN 설명 및 정리 (21) | 2020.01.13 |



