<KNN (K-Neareast Neighbors)>

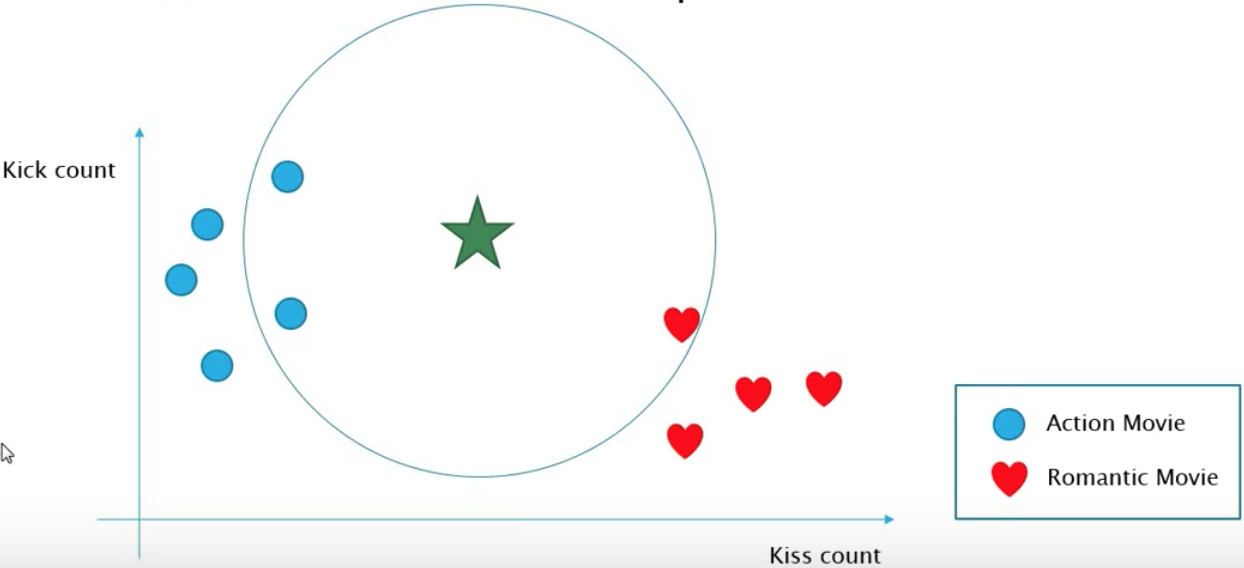
KNN은 위 그림과 같이 data들이 label이 지정된 상태로 분포되어있을때 새로운 new data에 대해서는 어떤 label을 지정해줄지 결정하기 위해 사용되는 알고리즘이다.
위 예시에서 파란색은 Action movie, 빨간색은 Romantic movie로 label이 지정돼있다.
이때 두 label을 구분하기 위한 parameter로 Kiss count, Kick count가 사용되었고 이에 기반했을때 녹색(new data)은 위와 같이 위치하게 된다. 그럼 저 new data는 Action movie / Romantic movie 중 어느 영화로 구분하는게 맞을까?
KNN의 동작과정은 다음과 같다.
- 새로운 data의 label을 지정하기 위해 근접한 K개의 data 정보를 이용한다.
- K를 지정해준다. (이때 K는 홀수이여야 한다.)
- 근접한 K개의 data에서 label의 개수를 count한다.
- 가장 많이 count된 label이 new data의 label로 결정된다.
위 그림은 k=3으로 했을때의 KNN 동작과정이다.
new data로부터 기존의 data들간의 거리를 모두 구한 후 가장 가까운 순으로 정렬하여 미리 지정한 k개 까지만 data의 label을 확인한다. 위 예시에서는 Action movie=2, Romantic movie=1로 결국 new data는 Action movie로 결정된다.
이때 k가 짝수라면 두 label이 동일한 count값을 가질 수 있으므로 이때는 가장 많이 count된 label 1개를 결정할 수가 없다. 따라서 k는 홀수로 정해줘야한다.
<Decision Tree>

위 이미지들이 주어졌을때 겨울에 찍은 가족사진을 찾는 task가 있다고 해보자.
이를 tree를 이용해서 해결한다면 3가지 attribute를 제시할 수 있다.
1. 사람사진인가 만화캐릭터 사진인가
2. 겨울에 찍은 사진인가
3. 1명이 아닌 여러명의 사람이 등장하는가
따라서 위 조건에 따라 tree를 구성하면 아래와 같다.

기존에 주어진 이미지들을 3개의 조건을 이용해 구분하여 Decision Tree를 만들었다.
만약 이후에 오른쪽과 같이 추가적으로 몇장의 사진이 input으로 더 들어온다면 기존에 만든 Tree에 추가할 수가 있다.

Decision Tree의 동작과정은 아래와 같다.
- 수행하고자하는 task를 정의하고 Data를 준비한다.
- Decision Tree를 만들기 위해 몇가지 attribute을 정의하여 이에 따른 matrix를 만든다.
- 최적의 Decision Tree를 설계한다.
이때 최적의 Decision Tree란 무엇일까?
위에서 Tree를 구성하는 3가지 attribute가 존재했었다. 이때 순서를 어떻게하냐에 따라 서로다른 Tree가 만들어진다.
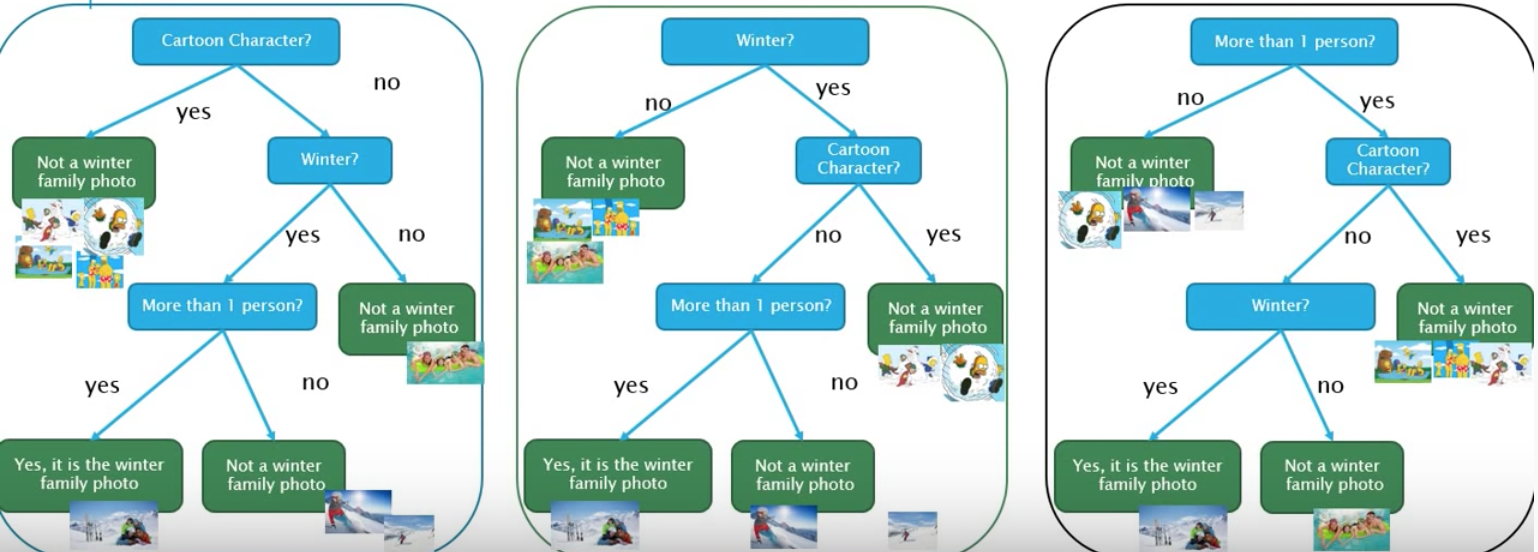
차례로 살펴보면 좌측 Tree는 첫 attribute로 4장을 split하고 중앙 Tree와 우측 Tree는 3장을 split한다.
이후에 Entropy와 Information Gain에 관해 논할텐데, 그러기전에 직관적으로 설명하자면
가장많은 이미지를 split하는 Tree일수록 좋다. 따라서 좌측 Tree를 선택한다.
이후에는 위 과정을 반복해서, 남은 두 attribute 중 더 많은 이미지를 split하는 attribute을 채택하여 Tree를 만든다.
이제 최적의 Decision Tree를 만들기 위해 어떤 attribute 순으로 Tree를 구성할지 더 자세하게 논해보자.
Decision Tree에서 하나의 attribute를 잡고 Data를 나눌때 여러 알고리즘이 있지만 여기서는
Entropy와 Information Gain을 이용하는 알고리즘인 ID3 Algorithm에 대해 설명한다.
Entropy
엔트로피는 Data에서 최종적으로 찾고자하는 task data의 비율을 나타내는 지표이다. 식은 다음과 같다.

Information Gain
Information Gain은 [base entropy - new entropy]로 이 값이 큰걸로 다음 attribute를 선정한다.
이제 실제로 수학적인 수식을 적용하여 최적의 Decision Tree를 찾아보자.

좌측은 미리 정의한 attribute에 따라 matrix를 만든 것이고 우측은 matrix를 참고하여 Information Gain을 계산한 것이다.
먼저 첫번째 Tree부터 보자.
맨 처음 attribute로 나누지 않았을때 Base entropy부터 계산하면 8개의 이미지 중 1개만 task data에 해당하므로

위 식과 같이 Base entropy를 계산할 수 있다.
다음에 cartoon이라는 attribute로 나누면 4개씩 이미지를 split한다. 이렇게 두 부분집합으로 분할했을때
엔트로피를 구하는 공식은 다음과 같다.

Ri는 분할했을때 data의 비율이다.
cartoon attribute로 나누면 4개씩 split되므로 R1, R2는 모두 4/8이다. 그다음 분할된 각 부분집합에서의 엔트로피는
cartoon쪽 4장의 이미지는 모두 task data에 해당되지 않으므로 Entropy[0+, 4-] 이고
cartoon이 아닌쪽 4장의 이미지 중 1장만 task data에 해당하므로 Entropy[1+, 3-] 이다.
위 두 Entropy를 더한 값이 attribute를 적용한 후의 entropy이다. 따라서 Information Gain은
[Base entropy - New entropy] 이므로 아래 식처럼 계산됨을 확인할 수 있다.

이러한 과정들을 반복했을때 cartoon attribute로 나눴을때의 Information gain이 가장 크므로 첫번째 attribute는 cartoon으로 한다. 결과적으로 이렇게 Information gain이 큰 attribute로 Decision Tree를 만드는 것이다.
그림 및 강의 출처 : https://www.youtube.com/user/TheEasyoung