logistic regression : binary classification을 하기위해 사용되는 알고리즘이다. y가 1일 확률을 계산하며 이때 시그모이드 함수를 이용하여 0~1사이의 값으로 만들어준다.
first-order method : 한번 미분한 변수로만 이루어진 식 (ex. 위에서 언급한 Gradient Descent)
element wise : 행렬, 벡터에서 원소별로 연산을 하는 것을 의미한다.
ex. element wise product에서는 일반적인 행렬곱셈이 아닌 원소별 곱셈이다.
따라서 곱셈할 행렬의 shape이 같아야 한다.
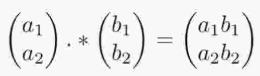
(행렬의 shape이 다르더라도 행렬 broadcast를 통해 shape이 같아질 수 있으면 가능하다.)
hyper parameter : 모델링할때 사용자가 직접 세팅하는 값이다. 일반적으로 heuristic한 방법이나 경험에 의해 결정한다.
모델 혹은 데이터에 의해 결정되면 parameter / 사용자가 직접 설정하면 hyper parameter이다.
(ex. layer수, learning rate, batch size, loss function, optimizer, weight decay rate, weight 초기값, epoch ...)
regret bound : 일반적으로 강화학습, MAB문제의 톰슨샘플링 알고리즘 등.. 에서 많이 사용되는 용어이다. 내가 선택한 model / policy를 이용하여 얻은 reward가 최선의 선택에 비해 얼마나 손해가 있는지를 수치화 한것을 regret이라 한다. regret bound는 이 regret의 bound, 즉 regret 범위정도로 생각하면 될 것 같다.
objective function : 학습을 통해 optimize시키려는 목적 함수이다. 일반적으로 우리가 알고 있는 cost function이 objective function의 한 종류이다.
adaptive learning rate : 맞춤 학습 속도. 일반적으로 GD, SGD, Momentum과 같은 optimizer들은 모든 parameter에 대해서 똑같은 학습 속도(똑같은 양만큼 update 된다)를 갖는다. 그러나 AdaGrad, RMSProp, Adam .. 에서는 각 parameter마다 서로 다르게 update된다. 예를 들어, AdaGrad에서는 지금까지 update양이 많았던 parameter일수록 학습률(학습속도)를 낮추고 아직 초기값에 비해 update가 거의 되지 않은 parameter는 학습률(학습속도)를 높인다.
sparse gradient problem : gradient가 희미해지는 현상이다. high-dimensional parameter 공간, 즉 hidden layer가 아주 깊으면 training signal이 약해져서 parameter가 효과적으로 update되지 않는다. 혹은 training data가 parameter를 효과적으로 update 시킬만큼 충분히 임팩트있는 signal이 아닐 경우 backpropagation에 의해서 gradient가 아주 희미해질 수 있다. vanishing gradient problem이 sparse gradients의 하나의 예이다.
step decay : step마다 일정 양만큼 learning rate를 줄이는 기법이다.
보통 5epoch마다 반으로 줄이거나 20epoch마다 1/10씩 줄이는 방법이 많이 쓰인다.
<exponential moving average>
지수 이동평균. 이 개념을 설명하기 앞서 먼저 average와 moving average를 비교해보자. average는 동일시점에서 산출되는 평균 값인데 반해 moving average는 시간이라는 개념이 도입됐을때 산출되는 평균 값이다. 예를들어, 동전을 던지는데 9번 연속 앞면이 나오면 다음 번에는 높은 확률로 뒷면이 나올거라 기대하는 것과 같다. 시간이라는 개념이 도입될 경우 최근의 정보가 더 많은 영향력을 미칠 수 있기 때문이다. 여기서 exponential moving average란 최근 data에 지수적으로 높은 가중치를 주는 것이다.
(ex. Momentum optimizer를 보면 오래된 data일수록 베타를 계속 곱하기때문에 지수적으로 가중치가 낮아진다.)

<trust region>
trust region은 이차미분을 이용한 최적화 기법의 단점을 극복하기 위한 방법이다. 이차미분을 이용하면 일차미분을 이용했을 때보다 더 빠르게 학습되고 hyper parameter(learning rate)가 없어도 된다. 그러나 변곡점에서 학습이 잘 되지 않고 극대, 극소를 구분하지 못한다. (반대로 일차미분은 느리긴하지만 학습 방향이 언제나 옳다)
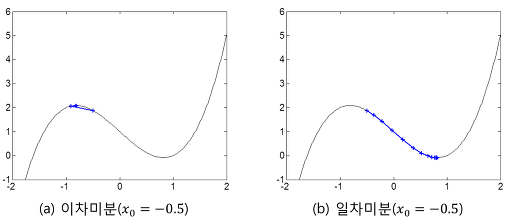
사실 trust region 방법은 복잡한 함수의 변화를 좀더 단순한 함수로 근사(approximation)할 경우에 근사 정확도를 보장하기 위해서 사용되는 일반적인 방법이지만 여기서는 이차함수로 근사하는 경우로 한정하여 설명한다.
앞서 설명했듯이 이차미분을 이용한 최적화 기법의 핵심 원리는 모든 구간에서 함수의 이차미분(f'') 값이 상수라고 가정하고 함수의 변화를 이차함수(quadratic function)로 근사한 후 근사 함수의 극점으로 이동하는데 있다. 그런데, 이 가정의 가장 큰 문제점은 실제 함수는 이차함수가 아니라는데 있다.
Trust region 방법은 근사 함수에 대한 신뢰 영역(trust region)을 정의한 후 이동할 목적지에 대한 탐색 범위를 이 영역 내부로만 제한하는 방법을 말한다.
실제 구현 측면에서, 최소화시키고자 하는 함수를 f(x), 현재 위치를 x = xk, 현재의 trust region을 |x - xk| ≤ rk라 하면 먼저 식 (2) 등을 이용하여 다음으로 이동할 지점을 추정한다. 만일 이동할 지점이 trust region을 벗어날 경우에는 스텝의 크기를 줄여서 trust region를 벗어나지 않도록 (trust region의 경계와 만나는 지점으로) 위치를 수정한다. 이와 같이 결정된 지점으로 이동한 후 다시 trust region 방식의 탐색을 반복하는 구조이다. 이 때, trust region의 크기는 매 반복마다 조정될 수 있으며 근사 2차함수가 현재의 trust region 내에서 원래 함수를 얼마나 잘 근사하는지에 따라서 조정된다. 통상적으로 근사오차가 허용치 이하일 경우에는 trust region의 크기를 키우고 허용치 이상일 때에는 trust region의 크기를 줄이는 방법이 사용된다.
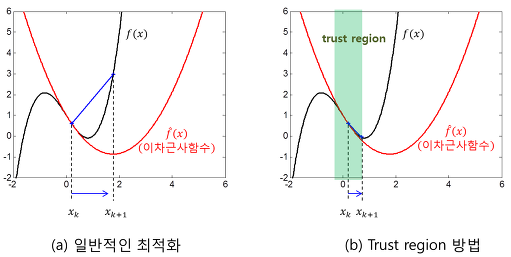
Trust region의 크기를 조절할 때, 현재의 trust region 내의 모든 지점에서 근사 오차를 확인하는 것은 비효율적이다. 따라서, 다음으로 이동할 지점에 대해서만 근사오차를 계산하여 trust region의 크기를 조정합니다. 그리고 필요하다면 trust region의 크기 조정에 따라 이동 지점도 같이 수정한다.
'인공지능 AI > 딥러닝' 카테고리의 다른 글
| Linear Regression vs Logistic Regression (0) | 2020.01.09 |
|---|---|
| Objective Function, Loss Function, Cost Function의 차이 (0) | 2020.01.09 |
| 딥러닝 공부순서 추천 (2) | 2020.01.04 |
| Optimizer 종류 및 정리 (0) | 2020.01.04 |
| 머신러닝 기초 (1. ML Basic) (0) | 2020.01.02 |


