<Introduction>
이전 글 : (논문리뷰&재구현) YOLACT 설명 및 정리 - (2)
(논문리뷰&재구현) YOLACT 설명 및 정리 - (2)
이전 글 : (논문리뷰&재구현) YOLACT 설명 및 정리 - (1) (논문리뷰&재구현) YOLACT 설명 및 정리 - (1) Image segmentation은 각 object에 대해 localization을 수행해야하므로 translation varia..
ganghee-lee.tistory.com
모델을 학습한 후 predict할때 image위에서 검출한 object의 class와 함께 bounding box가 그려진다.
이때 동일 object에 대해 여러 anchor box가 존재할 수 있는데 confidence(score)가 가장 높은 anchor box만 두고 나머지 중복되는 anchor box는 제거하기 위해 Non-maximum suppression 기법을 사용한다.
그리고 YOLACT에서는 NMS보다 약간의 성능저하로 높은 속도를 제공하는 Fast NMS 기법을 제시한다.
Fast NMS에 대해 살피기 전에 먼저 NMS 기법에 대해 살펴보자.
NMS
각 anchor box는 box branch에 의해 4개의 좌표와 class branch에 의해 81개 class에 대한 confidence값을 갖는다.
(실제로 anchor box들을 비교할때는 background class를 제외한 80개 class에 대한 confidence만 사용한다.)
anchor box들을 서로 for문을 두 번 중첩시켜 비교하면서 동일 instance를 focus하는 중복되는 anchor를 제거하는데
제거하는 과정은 다음과 같다.
- 80개의 class에 대해 for문으로 반복하면서 특정 class에 대한 confidence에 따라 anchor box들을 정렬한다.
- 특정 class의 confidence로 정렬됐을때 confidence가 높은 anchor box부터 for문을 통해서 전체 anchor box들과 IoU를 비교한다.
- 이때 두 anchor box의 IoU가 미리 지정한 IoU threshold보다 높다면 두 anchor box는 동일 instance를 focus한다는 뜻이므로 둘 중 confidence가 더 낮은 anchor box를 제거한다.
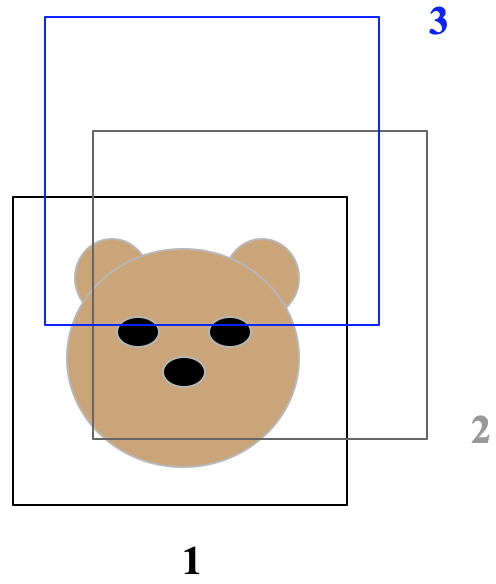
자세한 이해를 위해 그림과 함께 설명해보겠다. 위 그림을 보면 각각 anchor box가 confidence에 따라 정렬되어있다.
NMS 동작과정에 따라 차례대로 수행해본다면,
1번 anchor box와 2번 anchor box의 IoU가 threshold를 넘어가므로 2번 anchor box를 제거한다.
1번과 3번의 anchor box가 남은 상황에서 두 box의 IoU는 threshold를 넘어가지 않으므로 3번 anchor box는 그냥둔다.
즉, 핵심은 두 anchor box의 IoU가 threshold보다 높아서 겹쳐져 있다면 그 중 confidence가 낮은 anchor box를 제거하는 것이다. 위와 같은 알고리즘으로 NMS를 수행하면 for문을 세 번 중첩하게 된다.
모든 class점수에 대해, 모든 anchor box에 대해 비교를 하므로 다소 정확할지 몰라도 time complexity가 너무 높다.
따라서 YOLACT는 NMS보다 약간의 성능저하로 높은 속도향상을 보이는 Fast NMS를 제시한다.
<Fast NMS>
NMS를 한줄로 쉽게 설명하자면, anchor들을 서로 비교해서
(1) 자신보다 confidence가 낮으면서, (2) IoU가 threshold보다 크면, 두 anchor가 동일 instance를 focus한다는 뜻이므로 confidence가 낮은 anchor를 지우는 방식이다.
Fast NMS의 동작과정도 먼저 쉽게 설명해보자면, anchor들을 서로 비교하는데 이때
(1) 자신보다 confidence가 높은 anchor들이랑만 비교를 했을때, (2) 자신과 IoU값이 제일 큰 anchor(자신과 제일 많이 겹치는 anchor) 가 threshold보다 작으면, 자신보다 confidence가 높은 anchor들 중에 같은 instance를 focus하는 anchor가 하나도 없다는 뜻이다. 따라서 해당 anchor는 지우지 않는다.
반대로 얘기하자면 자기보다 confidence가 높은 anchor중, IoU값이 제일 큰 anchor가 threshold보다 크다면 두 anchor는 동일 instance를 focus하는데 이때 자기가 더 낮은 confidence이므로 자기자신은 지우는 것이다.
이를 참고하여 Fast NMS의 동작과정을 step-by-step으로 살펴보자면 다음과 같다.
- NMS와 마찬가지로 80개 class에 대해 for문으로 반복하면서 특정 class에 대한 confidence로 anchor들을 정렬한다.
- anchor들끼리 서로 IoU를 계산하여 IoU matrix를 생성한다.
- IoU matrix에서 우측상단 값들만 두고 나머지는 지운다.
- IoU matrix에서 각 column에서 가장 큰 값(IoU가 가장 높은 값)들만 뽑아서 K matrix를 만든다.
- K matrix에서 IoU threshold값인 t보다 작은 value만 두고 threshold를 넘어가는 value는 제거한다.

좌측에 있는 matrix는 anchor들을 먼저 confidence로 내림차순 정렬한 후 서로 IoU를 계산한 matrix이다.
이때 우측 상단 값만 두고 대각선을 포함한 좌측 하단의 값들을 지우는 이유는 자신보다 confidence가 높은 anchor들과만
IoU를 비교하기 위함이다. 이제 자신보다 confidence가 높은 anchor들 중 가장 IoU가 높은 value를 뽑아낸다.
이는 column별로 가장 높은 value를 뽑아내면 된다. 이 과정을 통해 max IoU value로 구성된 K matrix를 만든다.
다음으로 max IoU value가 threshold를 넘어가는지 비교하기 위해 K < t를 계산하여 이 식을 만족하는 값만 남겨둔다.
최종적으로 자신보다 confidence가 높은 anchor들 중 자기자신과 IoU가 threshold이상으로 겹치는 anchor가 없다면
자신이 focus하고있는 instance에 대해 가장 높은 confidence를 갖고있는 anchor가 바로 자기자신이라는 뜻이다.
"즉, 해당 instance를 focus하고 있는 수많은 anchor들 중 confidence가 제일 높은 anchor가 자기자신인 것"
NMS와 마찬가지로 그림과 함께 설명해보겠다.
NMS에서 설명했듯이 NMS 동작과정에 의해서 위 그림에서 2번 anchor box가 제거된다. 이번에는 Fast NMS로 해보자.
위 예시는 간단하므로 직관적으로 이해할 수 있어 IoU matrix를 만들지 않고 설명해보겠다.
먼저 2번 anchor box의 경우 자신보다 confidence가 높은 1번 anchor box와의 IoU가 threshold를 넘어가므로
2번 anchor box는 지워지게 된다. 여기서 NMS와 Fast NMS의 또 다른 차이는 NMS는 2번 anchor box가 지워지면
더이상 2번 anchor box는 어떠한 anchor box와도 비교를 하지 않는다. 그러나 Fast NMS에서는
"이미 지워진 anchor box가 또 다른 anchor box를 지우기 위해 비교를 계속해나간다."
NMS에서는 동작과정, 즉 anchor box를 제거하는 과정이 순차적으로 이뤄지지만 Fast NMS는 병렬로 진행된다.
따라서 이미 2번 anchor box가 지워졌지만 3번 anchor box를 대상으로 Fast NMS를 한다 생각해보면
자신보다 confidence가 높은 2번 anchor box와의 IoU가 threshold를 넘어가므로 3번 anchor box도 지운다.
이렇게 Fast NMS는 NMS보다 anchor box를 더 많이 제거하기 때문에 약간의 성능저하가 있다고한다.
그러나 NMS와 달리 행렬연산을 하므로 GPU로 수행할 수 있어 더 빠르고
for문을 세번이나 중첩하지 않고 행렬로 동시에 병렬로 수행하므로 for문을 한 번만 이용한다.
이에 따라 약간의 성능저하로 월등한 속도향상을 보이는 것이다.
<Summary>
지금까지의 내용들을 정리하자면 Protonet과 Prediction Head를 통해서 나온 prototype mask와 coefficient들을
linear combination을 통해 결합하여 최종 mask를 생성한다. 이때 Prediction Head에서 생성되는 모든 anchor에 대해
linear combination을 하는 것이아니라 anchor들을 Fast NMS를 통해서 중복되는 anchor들은 제거한다.
그 후 남겨진 anchor들에 해당하는 coefficient값과 prototype mask를 combination해서 최종 mask를 생성한다.
마지막으로 YOLACT모델을 학습시키기 위해 사용되는 Loss는 다음과 같다.

기존의 다른 object detection 모델들과 마찬가지로 Classification Loss와 Bounding box Loss가 있다.
거기에 Image segmentation이므로 Mask Loss가 추가되었다.
다음 글에서 Loss에 대해서 설명하고 YOLACT 논문리뷰 & 재구현코드 설명을 마치겠다.
다음 글 : (논문리뷰&재구현) YOLACT 설명 및 정리 - (4)
(논문리뷰&재구현) YOLACT 설명 및 정리 - (4)
YOLACT모델을 학습시키기 위해 사용되는 Loss는 다음과 같다. YOLACT에서 Loss는 Classification loss, Bounding box loss, Mask loss로 구성돼있다. 이때 각각의 loss가 가중치가 서로 다른데,..
ganghee-lee.tistory.com
'인공지능 AI > 논문리뷰 and 재구현' 카테고리의 다른 글
| (논문리뷰) Associative embedding : End-to-End Learning for Joint Detection and Grouping 설명 및 정리 (0) | 2020.07.17 |
|---|---|
| (논문리뷰&재구현) YOLACT 설명 및 정리 - (4) (5) | 2020.03.22 |
| (논문리뷰&재구현) YOLACT 설명 및 정리 - (2) (3) | 2020.03.19 |
| (논문리뷰&재구현) YOLACT 설명 및 정리 - (1) (4) | 2020.02.16 |
| (논문리뷰) ResNet 설명 및 정리 (8) | 2020.02.08 |



