<Introduction>

위 사진에서 첫번째 행에서 보이는 것과 같이 Image에서 사람의 pose를 추정하는 person pose estimation과 두번째 행에 있는 instance segmentation문제는 보통 2-stage로 진행됐었다. (detecting stage & grouping stage)pose estimation에서는 먼저 머리, 어깨, 팔꿈치, 손, 등.. 에 해당하는 위치(body joint)를 point로 잡아내고 (Figure 1. - 1행 2열) 각 body joint를 사람 별로 grouping한다. (Figure 1. - 1행 3열)
Instance segmentation에서는 각 pixel 별로 instance (foreground)에 해당하는 pixel인지 binary로 판별하고 (Figure 1. - 2행 2열) 각 pixel들을 instance 별로 grouping한다. (Figure 1. - 2행 3열)
이 논문에서는 이러한 detecting 작업과 grouping 작업을 동시에 수행할 수 있는 즉, single-stage 방법인 Associative embedding method를 제시한다. 이 method의 basic idea는 joint detection을 함과 동시에 각 detection에게 어떤 그룹에 속하는지를 뜻하는 "tag"를 숫자로 부여한다. 즉, pose estimation에서 여러 body joint들이 존재할텐데 각 joint마다 "tag"가 존재하고 동일 "tag"인 joint들은 같은 group으로 묶이고 다른 "tag"인 joint들은 서로 다른 group으로 묶인다. (ex. 0~1 사이의 "tag"가 할당된 joint들은 같은 그룹, 1~2 사이의 "tag"가 할당된 joint들은 같은 그룹, "tag"가 1과 2인 두 joint는 서로 다른 group ...)
해당 논문의 Contribution은 두 가지이다.1. 새로운 single-stage method인 Associative embedding 을 통해 detecting과 grouping을 동시에 수행한다.2. 이를 multi-person pose estimation에 적용했을때 SOTA에 상응하는 성능을 보였다.
<Stacked Hourglass Network>

해당 논문에서 사용된 network에서는 먼저 각 pixel별로 body joint들에 대한 detection score를 예측하기 위해 stacked hourglass network를 사용한다. (Stacked hourglass network : https://arxiv.org/abs/1603.06937)
Stacked hourglass network는 Feature pyramid network와 아주 유사하다.
(Feature Pyramid Network에 대한 설명은 아래 글에서 확인할 수 있다)
2020/02/08 - [인공지능 AI/논문리뷰&재구현] - (논문리뷰&재구현) Mask R-CNN 설명 및 정리
(논문리뷰&재구현) Mask R-CNN 설명 및 정리
이전글 : (논문리뷰) Faster R-CNN 설명 및 정리 Faster R-CNN 설명 및 정리 이전글 : Fast R-CNN 설명 및 정리 Fast R-CNN 설명 및 정리 이전글 : Object Detection, R-CNN 설명 및 정리 Object Detection, R-CNN..
ganghee-lee.tistory.com
FPN에 대해서 간단히 정리하자면, Backbone network에서 복수개의 Convolution layer를 거치고 마지막 feature map만 이용하여 다음 step으로 보낼 경우 resolution이 매우 작아져 receptive field가 커진다. 이는 small object들에 대해서 정확한 detection이 어렵고 Convolution layer들을 거쳐갈수록 이전 feature들의 정보들을 잃어버리게 된다. 따라서 다시 Bottom-up 형식으로 이전 feauture map을 upsampling하면서 이전 feature map을 더함으로써 다양한 scale의 object들에 대해서 detection이 더 정확해지고 이전 feature 정보들을 잃어버리지 않게된다.
Hourglass network에서도 마찬가지로 마지막 feature map을 upsampling하면서 이전 feature map을 더하는 형식으로 Bottom-up 과정을 갖는다. FPN과의 차이점은 FPN는 주로 object detection에서 사용될때 여러 scale의 object에 대해서 robust해지기 위해 Bottom-up 과정에서 생성된 feauture map (F5, F4, F3, F2) 모두를 다음 step 으로 넘긴다.
하지만 Hourglass network에서는 Bottom-up 과정을 모두 거친 마지막 feature map만을 다음 step 으로 넘긴다.
Hourglass network는 위 과정을 통해 final prediction인 body joint에 대한 heatmap이 output으로 나오게 된다.
<Associative embedding>
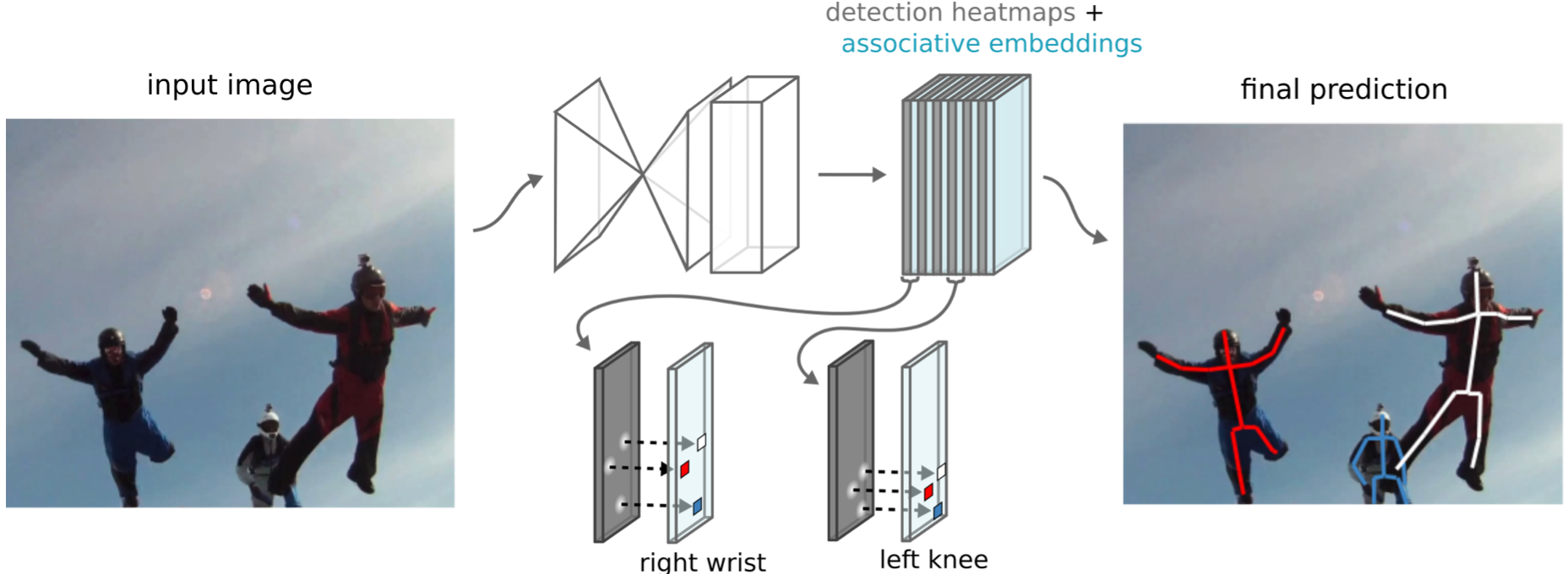
Hourglass network에서 body joint에 대한 heatmap이 생성된 후 associative embeddings에서는 이 heatmap을 이용해서 detection 생성과 grouping을 동시에 수행한다. 각각의 body joint(1, ... , k)에 대해서 pixel 별로 detection score와 "tag" value를 갖게 되므로 m개의 body joint가 존재한다면 detection을 위한 m개의 channel과 grouping을 위해 "tag"를 할당한 heatmap m개가 생성돼서 총 2m개의 channel이 생성된다.
최종적으로 body joint 별로 detection score와 "tag" value 두 가지를 고려하여 final prediction을 생성한다.
(Figure 3. 가장 우측 사진)
<Loss - pose estimation>
해당 논문에서는 위 network를 두 가지 task에 적용했다. (multi-person pose estimation, Instance segmentation)
먼저 pose estimation에서 적용했을때 loss를 살펴보면 다음과 같다.
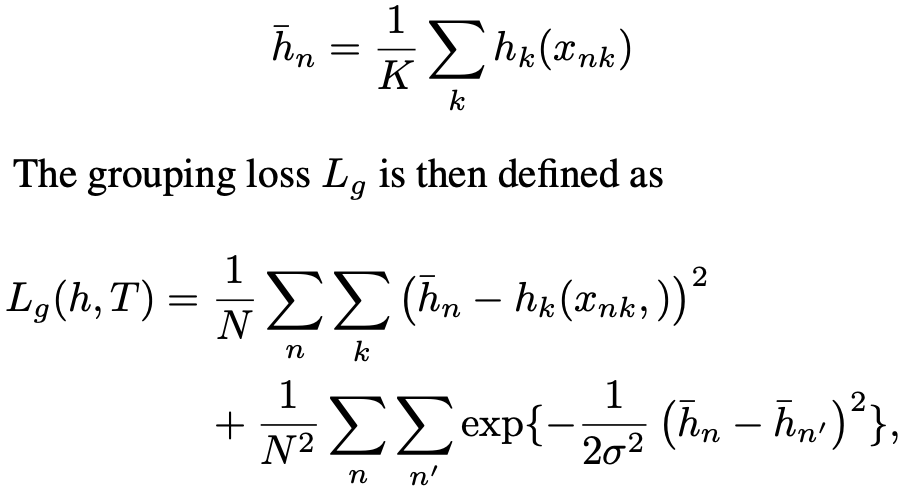
detection loss는 단순히 ground truth heatmap과 Mean squared error를 통해 계산되므로 생략하겠다.
grouping loss는 조금 다른게, ground truth와 prediction을 비교하여 loss를 계산하지 않는다.
"tag" value를 할당할때 단순히 같은 group은 비슷한 "tag", 다른 group은 서로 다른 "tag"를 할당시키면 되기 때문에 각 body joint 별로 ground truth "tag" value를 고려하는 것은 무의미하다. (ex. 어떤 두 body joint가 같은 group 이라면 "tag" value로 1, 2, 등 ... 어떤 값을 갖든 상관없이 비슷한 value를 갖기만 하면된다. - any value but! similar value)
따라서 "tag"에 대해서는 ground truth값을 고려하지 않고 prediction 값을 통해 reference embedding을 구한다.
위 그림에서 h bar에 해당하는 변수가 reference embedding이다. 이는 n번째 사람에 할당된 "tag"인데, n번째 사람에 대응되는 k개의 body joint의 prediction "tag" 값들을 평균내서 구한다. 즉, 어떤 사람한테 3개의 body joint가 검출됐는데 각 body joint에 할당된 "tag" value가 1, 1, 2라면 reference embedding은 4/3 값이 된다.
따라서 이 reference embedding과 prediction "tag" value들을 이용하여 loss를 구하는데
첫번째 항은 어떤 사람에 대해 계산된 reference embedding값과 해당 사람에서 검출된 k개의 body joint의 "tag"값 사이의 squared distance를 계산한 것이다. 그리고 두 번째 항은 서로 다른 사람에 대해서 reference embedding값들이 차이를 가우시안을 통해 계산한 것이다.
train과정을 통해 loss식이 의미하는 것은 첫 번째 항, 즉 동일 사람내에서의 body joint의 "tag" value들은 서로 같아질수록 loss가 줄어들고 두 번째 항, 즉 서로 다른 사람인 경우 reference embedding 값의 차이가 커질수록 loss가 줄어든다.
<Loss - Instance segmentation>

Instance segmentation에서의 grouping loss식도 위와 비슷한데 한 가지 다른 점은 pixel-wise로 계산하지 않는다는 점이다. multi-person pose estimation에서는 k개의 body joint(실제로는 n명이 있으니까 nxk 개)에 대해서만 grouping을 수행하면 되므로 k개의 "tag" 값만 이용해서 loss를 계산하므로 computation cost가 그리 크지 않다. 하지만 instance segmentation의 경우 모든 pixel에 대해서 grouping을 수행해야 하므로 모든 pixel의 "tag" value를 이용해서 loss를 계산할 경우 cost가 커지게 된다. 따라서 인접 pixel들을 sampling해서, 즉 random하게 kxk size의 pixel을 뽑아서 이들의 "tag" value를 이용하여 loss를 계산한다.
그림 출처 : https://arxiv.org/abs/1611.05424
'인공지능 AI > 논문리뷰 and 재구현' 카테고리의 다른 글
| (논문리뷰) iCAN : Instance-Centric Attention Network for Human-Object Interaction Detection 설명 및 정리 (0) | 2020.07.20 |
|---|---|
| (논문리뷰) PointNet : Deep Learning on Point Sets for 3D Classification and Segmentation 설명 및 정리 (2) | 2020.07.18 |
| (논문리뷰&재구현) YOLACT 설명 및 정리 - (4) (5) | 2020.03.22 |
| (논문리뷰&재구현) YOLACT 설명 및 정리 - (3) (2) | 2020.03.20 |
| (논문리뷰&재구현) YOLACT 설명 및 정리 - (2) (3) | 2020.03.19 |



