<Introduction>
이전 글 : (논문리뷰&재구현) YOLACT 설명 및 정리 - (3)
(논문리뷰&재구현) YOLACT 설명 및 정리 - (3)
이전 글 : (논문리뷰&재구현) YOLACT 설명 및 정리 - (2) (논문리뷰&재구현) YOLACT 설명 및 정리 - (2) 이전 글 : (논문리뷰&재구현) YOLACT 설명 및 정리 - (1) (논문리뷰&재구현) YOLACT 설명..
ganghee-lee.tistory.com
YOLACT모델을 학습시키기 위해 사용되는 Loss는 다음과 같다.

YOLACT에서 Loss는 Classification loss, Bounding box loss, Mask loss로 구성돼있다.
이때 각각의 loss가 가중치가 서로 다른데, 차례대로 1 : 1.5 : 6.125의 가중치를 갖는다.
즉, 최종 Loss는 1*Lcls + 1.5*Lbox + 6.125*Lmask 인 셈이다.
<Classification Loss>
YOLACT는 Class Imbalance문제를 위해 OHEM으로 Hard negative와 Positive example을
3:1 비율로 뽑고 학습을 위해 이들의 loss만 사용한다.

생성된 19248개의 모든 anchor들에 대해서 classification loss를 구한다.
(* Fast NMS같이 하나의 instance에 대해 중복 앵커를 제거하고 가장 높은 confidence를 가진 앵커만 남기는 기법은
학습이 다 끝나고 predict(eval)할때만 적용하는 기법이다. Train시에는 모든 앵커에 대한 loss를 계산한다.)
1. Negative example data 추출
각 앵커는 81개의 각각의 클래스에 대해 confidence를 갖고있다. 앵커가 갖고있는 81개의 confidence값을
softmax를 통해서 최종 confidence값 1개로 수렴시킨다. 여기서 negative를 제외한 값들은 지워주고
남은 negative example들을 confidence가 높은 순으로 정렬한다.
2. Positive & Hard negative example data 추출 (OHEM)
positive_bool은 19248개의 앵커들을 ground truth box들과 IoU를 계산해서 positive exmaple인 앵커들의
index를 모아놓은 리스트이다. conf_gt는 앵커들과 gt box들의 IoU를 계산해서
positive이면 class label, negative는 0, neutral은 -1 로 값을 넣은 리스트다. 위에서 추출한 negative examples과
이 두 변수를 이용해서 negative example들 중 confidence가 높은(=Hard negative examples) example들과 positive example들을 선별한다. 선별한 example들과 이들에 대응되는 ground truth사이의 loss만을 계산하는 것이다.
이때 cross entropy를 사용하는데 predict값인 class_p_selected의 shape은 [#examples, 81]이고,
target인 class_gt_selected의 shape은 [#examples, 1]로
80개의 confidence값들과 1개의 target사이의 cross entropy를 계산한다.
요악하자면, 모든 앵커들을 softmax를 통해서 81개의 confidence를 1개의 confidence값으로 수렴시키고 (정렬한다음
Hard negative example들을 선별하기 위해서) Positive, Hard negative example들을 추출하여
이들이 갖고있는 81개의 confidence값들과 ground truth이 갖고있는 1개의 class label 사이의 cross entropy값을
계산해서 Classficiation Loss를 계산한다.
<Bounding box Loss>
Bounding box loss의 경우 2-stage detector들과 동일하게 Smooth L1으로 구현되어있다.

(Bounding box Loss에 관해서는 Fast R-CNN 게시글에서 자세히 설명하고 있다.)
(논문리뷰&재구현) Faster R-CNN 설명 및 정리
(논문리뷰&재구현) Faster R-CNN 설명 및 정리
이전글 : (논문리뷰) Fast R-CNN 설명 및 정리 Fast R-CNN 설명 및 정리 이전글 : Object Detection, R-CNN 설명 및 정리 Object Detection, R-CNN 설명 및 정리 컴퓨터비전에서의 문제들은 크게 다음 4가지로 분..
ganghee-lee.tistory.com
<Mask Loss>

Mask Loss 해당 코드의 핵심부분만 보면 위와같다.
pos_coef 변수는 모든 anchor들에 대한 k개 coef를 담고있는 리스트에서 positive anchor들의 coef만 뽑은 것이다.
즉, positive anchor의 개수가 num_pos라면 (num_pos, k)의 shape을 갖는다.
protonet의 output에 이 변수를 transpose해서 곱하면 (138, 138, num_pos)로 linear combination mask결과가
num_pos개수만큼 있는 shape이다.
여기서 실제 anchor box의 영역을 제외한 pixel의 mask는 0으로 값을 수정해준다.
이제 실제 ground truth mask와 binary cross entropy로 각 pixel별로 bce를 계산한다.
각 pixel별로 구해진 loss를 각 object별로 다 더해서 모든 영역의 pixel loss를 더한 값이 num_pos만큼 나온다.
이때 실제 anchor box의 영역으로 나눠주는데, 그 이유는
동일 엄청 큰 box에서의 loss와 작은 box에서의 loss가 같다고 가정할때, 당연히 적은 개수의 pixel로 loss를 계산한
작은 box가 pixel-wise하게 더 큰 loss를 갖기 때문이다.
이렇게 각각의 box 영역넓이로 loss를 나누고 num_pos개수만큼 나온 loss들을 다 더한다.
마지막으로 prototype넓이인 (138*138)로 나누고 Mask Loss에 부여된 가중치 6.125를 곱한다.
<Segmentation Loss>
YOLACT의 두개의 병렬 subtask중 하나인 Prediction Head에는 Class, Box, Mask 이렇게 3개의 branch가 있다.
그리고 각각의 branch에서 anchor와 Prototype Mask를 이용해서 Loss를 계산하고
위에서 각각 3개의 Loss에 대해서 설명했다.
그러나 사실 YOLACT에는 오로지 "Train"을 위해서 사용되는 branch가 있다.
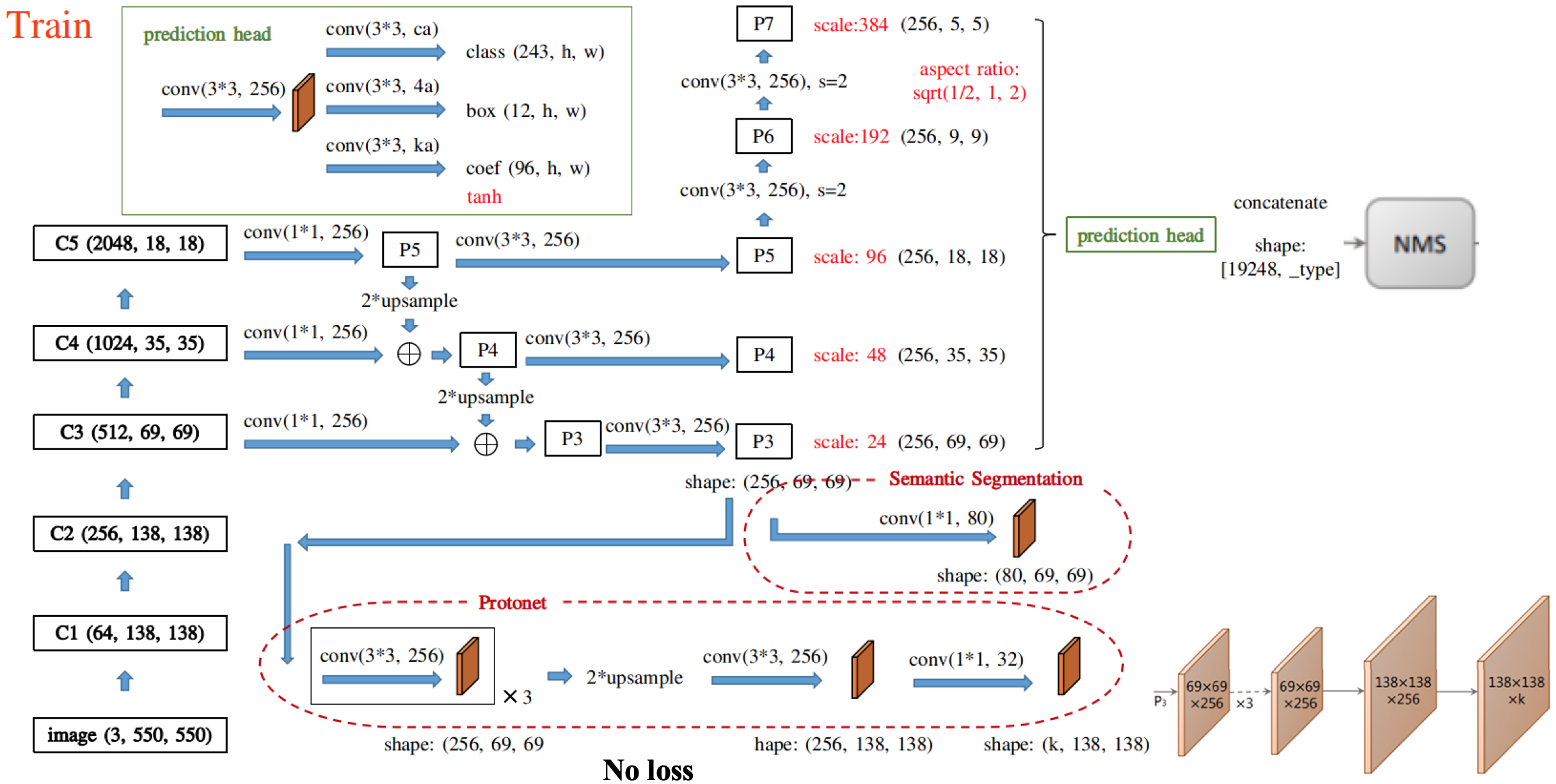
위 그림은 실제로 "Train"할때의 YOLACT 모델을 디테일하게 그린 것이다.
그림에서 확인할 수 있듯 FPN 으로부터 생성된 5개의 feature map은 protonet, prediction head의 input이 된다.
이때 자세히보면 Semantic Segmentation branch라는 이전에 보지못한 branch가 있음을 확인할 수 있다.
모델을 학습시킨 후 predict할때는 사용하지 않는 branch이지만 수월한 train을 위해 별도로 이 branch를 사용한다.
Semantic Segmentation에서의 Loss는 다른 Image segmentation에서의 segmentation loss와 다르지 않다.

Segmentation branch를 train할때 사용되는 예측값은 P3이고 target은 ground truth Mask이다.
기존의 ground truth Mask를 P3의 shape가 맞춰주기 위해 69x69로 downsampling을 해준다.
이때 ground truth mask는 하나의 object에 대한 mask값이므로 동일 class에 대해서는 mask를 합쳐준다.(17~19)
그 후 loss를 구할때는 linear combination mask loss에서와 마찬가지로 BCE로 pixel-wise하게 계산한다.
pixel별 평균 loss를 이용하기 때문에 모든 pixel에서의 loss를 구한 후 69x69영역으로 나눈다.
이때 segmentation loss에 부여된 가중치는 1이므로 1을 곱해준다.
이상으로 YOLACT 논문에 대한 리뷰와 Loss에 관련된 코드 설명을 마쳤습니다.
해당 논문의 재구현 혹은 자세한 코드를 보고싶다면 아래 링크에서 확인하실 수 있습니다.
https://github.com/Kanghee-Lee/Yolact_Pytorch/blob/master/YOLACT.ipynb
Kanghee-Lee/Yolact_Pytorch
Pytorch implementation of the Yolact network proposed in 'Yolact : Real-time instance segmentation' paper - Kanghee-Lee/Yolact_Pytorch
github.com
코랩을 통해서 구현하였으며 쉽게 이해할 수 있도록 각각의 branch마다 결과화면도 모두 출력하였습니다.
또한 최대한 자세하게 line-by-line으로 주석달아서 코드를 이해하는데 큰 어려움이 없을 것입니다.
혹시나 이해가 안되는 부분이나 틀린 부분이 있다면 댓글로 알려주시면 감사하겠습니다.
'인공지능 AI > 논문리뷰 and 재구현' 카테고리의 다른 글
| (논문리뷰) PointNet : Deep Learning on Point Sets for 3D Classification and Segmentation 설명 및 정리 (2) | 2020.07.18 |
|---|---|
| (논문리뷰) Associative embedding : End-to-End Learning for Joint Detection and Grouping 설명 및 정리 (0) | 2020.07.17 |
| (논문리뷰&재구현) YOLACT 설명 및 정리 - (3) (2) | 2020.03.20 |
| (논문리뷰&재구현) YOLACT 설명 및 정리 - (2) (3) | 2020.03.19 |
| (논문리뷰&재구현) YOLACT 설명 및 정리 - (1) (4) | 2020.02.16 |



