<Introduction>
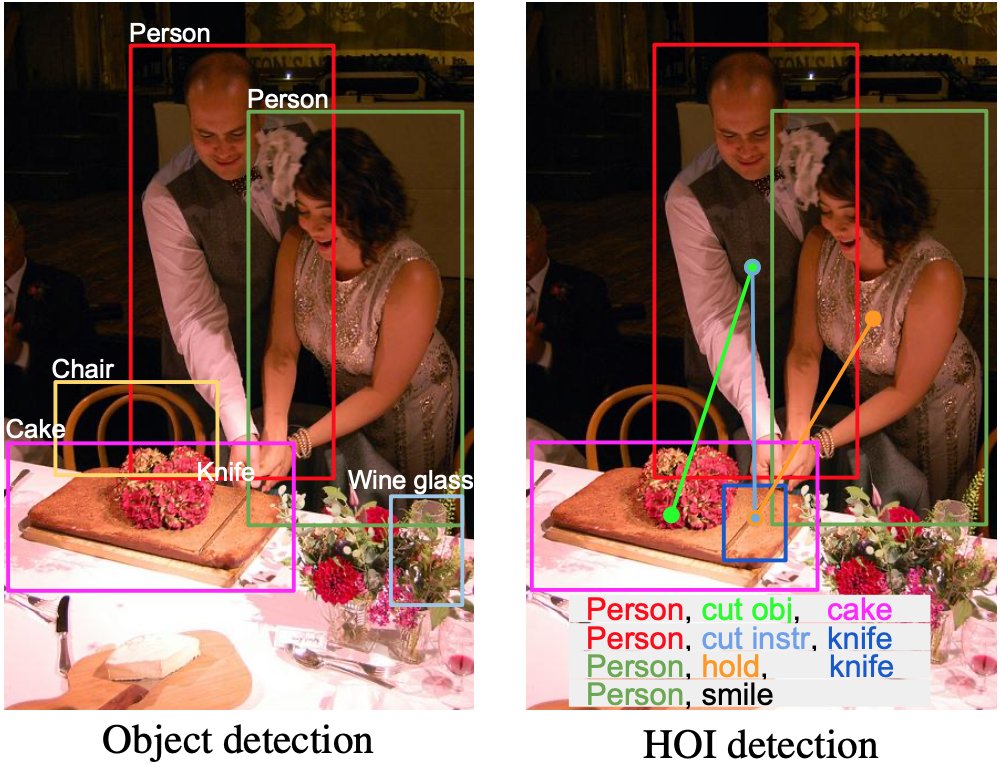
Object detection은 이미지에서 object에 대해 classification과 localization을 수행한다. 이때 object들간의 interaction에 대해서도 추론해볼 수 있는데 HOI는 object들 중에서도 특히 human과 object간의 interaction을 추론하는 task이다.
이런 HoI task에서는 기본적으로 <human, verb, object> 이 triplet을 찾는 것을 목표로 하고 있다.
최근 연구에서는 human 혹은 object의 appearance가 각각 이미지에서 어떤 부분(region)과 관련있는지에 대한 단서를 담고 있기 때문에 이를 기반으로 attention map을 만들어서 해결하려고 했었다.
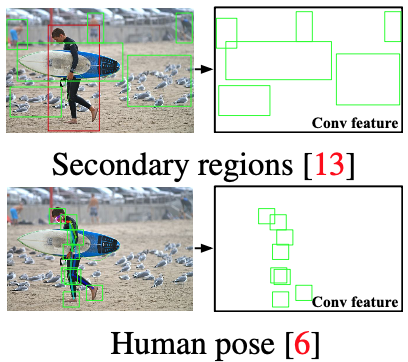
정확히는 attention map을 만들기 위해서 human, object의 bounding box뿐만 아니라 Figure 2 에서와 같이 human pose, secondary regions, .. 등과 같은 특징들을 모두 통합해서 attention map을 만들고 이를 통해 interaction을 추론했다. 하지만 이처럼 human pose, secondary regions들을 그대로 사용해서 attention map으로 사용하는 것은 human pose에 대해 학습하는 network가 존재하는 것이지 attention map을 생성하기 위해 학습하는 network가 존재하는 것은 아니다. 즉, network는 human pose를 생성하기 위해 학습되고 이를 다른 요소(bounding box, global feature, ...) 들과 결합해서 attention map을 직접 만든다. 이를 hand-designed attention map이라 한다.
따라서 논문에서는 interaction을 정확하게 추론하기 위해서는 attention map을 생성하는 것조차 end-to-end로 학습할 수 있는 network가 있어야 한다고 주장하며 instance-centric attention network를 제시한다.
이 iCAN은 human, object의 appearance를 이용하여 informative region을 강조하는 것(=attention map)을 network가 학습할 수 있도록 한다. 따라서 detect되는 human, object에 따라서 동적으로 attention map이 생성된다.
논문에서 제안된 model의 핵심적인 동작과정은 다음과 같다.
1. human/object appearance, contextual feature에 기반하여 interaction을 추론한다. (iCAN module)
2. human-object의 spatial relationship에 기반하여 interaction을 추론한다. (Spatial Configuration)
3. 각각의 stream(총 3개)으로 부터 계산된 interaction prediction을 결합하여 final prediction을 계산한다.
전체 네트워크부터 iCAN module까지 차례로 어떻게 구성되고 동작하는지 살펴보자.
<Networks>
최종적으로 구하고자 하는 final prediction은 아래와 같다.

위 식1 을 구하기 위해 전체 network는 3개의 stream으로 나누어져 있고 구조는 아래와 같다.
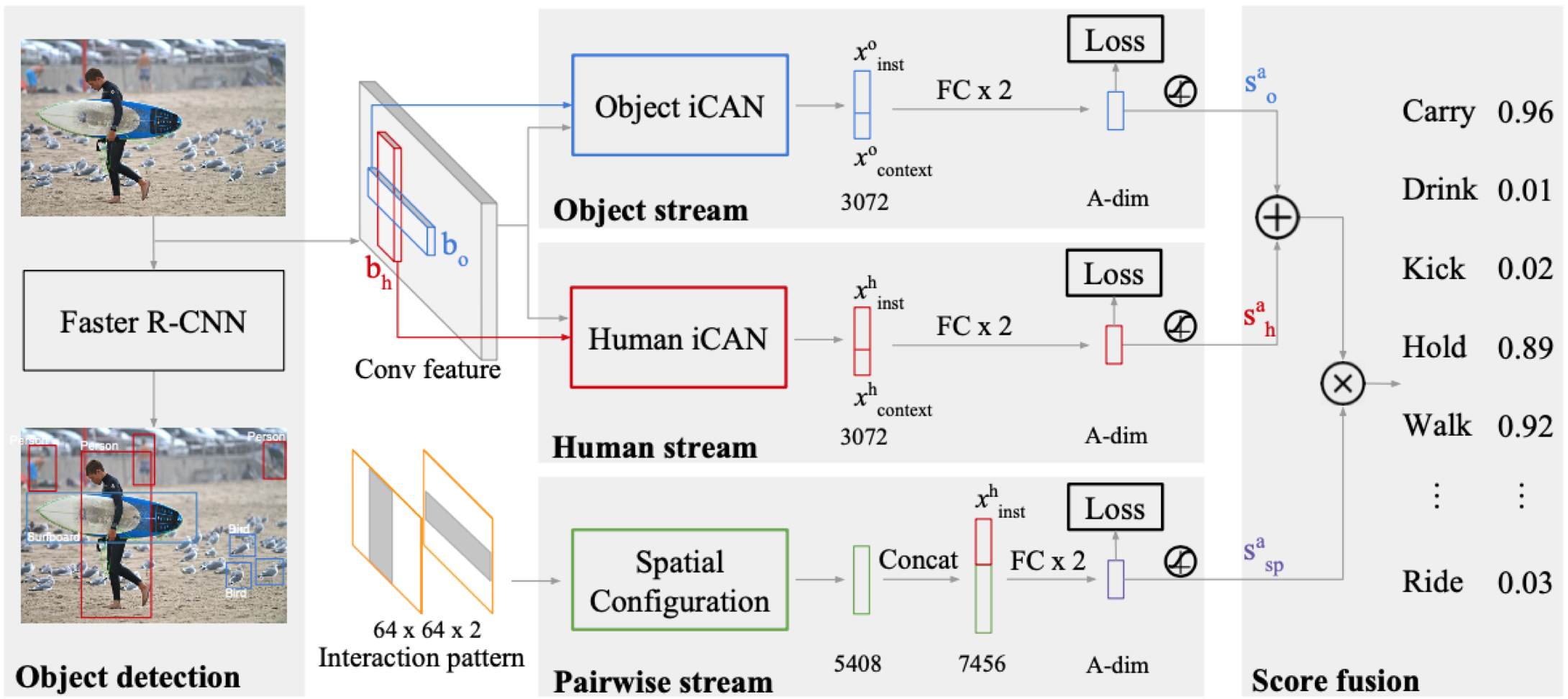
크게 3개의 stream으로 나누어져 있다. (human/object stream, Pairwise stream)
1. Human/Object stream : iCAN module을 통해서 instance의 appearance기반 feature(x^h_inst), attention-based contextual feature(x^h_context) 두 개를 구해서 concatenate시키고 이들로부터 human/object에 대한 interaction score prediction( 식 1-(2) )을 구한다.
2. Pairwise stream : human-object사이의 spatial relationship을 통해서 interaction score prediction( 식 1-(3) )을 구한다.
human/object에 대한 interaction score를 계산하기 위해서는 먼저 iCAN module에서 x^h_inst, x^h_context를 구해야 한다.
<iCAN>
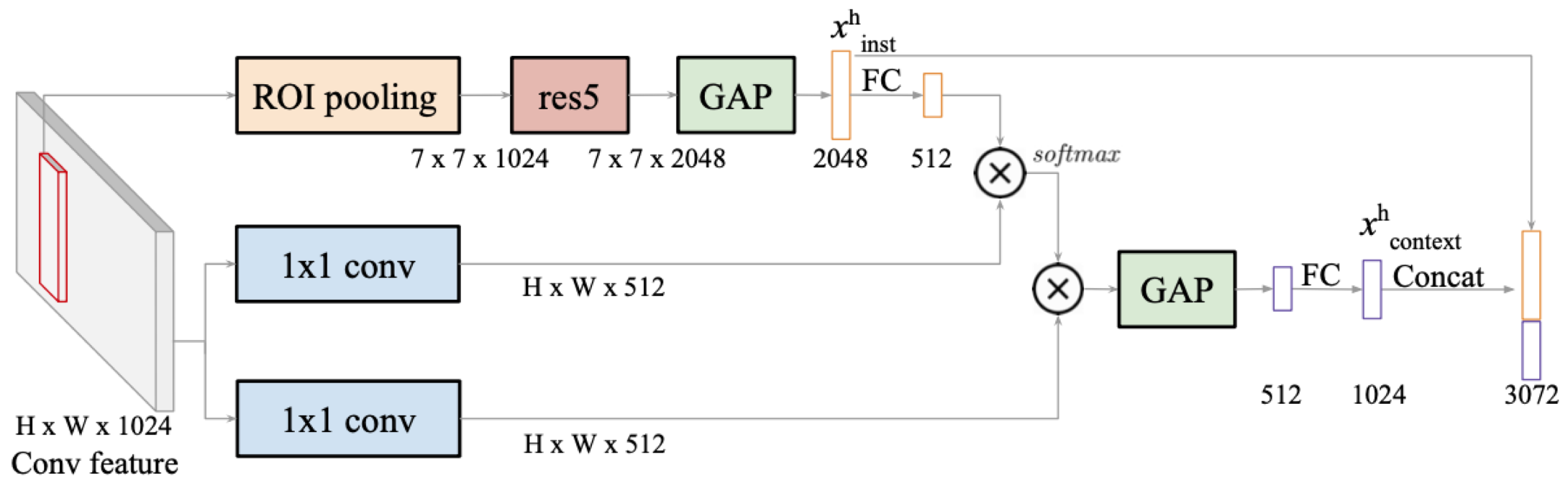
instance-level appearance feautre인 x^h_inst는 다음과 같이 구할 수 있다.
Faster R-CNN으로부터 RoI영역을 먼저 추출하고 res5를 통과시킨다.
instance의 feature map을 GAP연산을 통해 global feature를 뽑아내서 결국 instance-level appearance feature 2048개가 구해진다.
다음으로 attention-based contextual feature인 x^h_context는 다음과 같이 구한다.
위에서 구한 x^h_inst에 FC를 통과시켜서 해당 instance의 경우 어떤 region(feature)를 관심있게 봐야하는지를 뜻하는 attention weight(512)를 구한다. 여기에 전체 이미지에 대한 feature map인 HxWx512와 attention weight의 유사도를 vector dot product를 통해 구하면 이것이 바로 attention map(=주어진 instance를 기준으로 전체 이미지에서 어떤 region(feature)를 관심있게 봐야하는지를 내포하고 있는 map)이다. 이 attention map을 다시 전체 이미지에 대한 feature map에 곱한 후 GAP를 통해 global feature를 뽑아내면 attention-based contextual feature(=attention에 기반해서 전체 이미지에서 추출되는 global feature 1024개)가 구해진다.
정리하면 다음과 같다.
1. human/object의 bounding box로부터 local feature를 담고 있는 instance-level appearnce feature를 구한다.
2. 이미지 전체로부터 feature를 추출하고 여기에 이전에 구한 instance-level appearance feature를 적용하여 attention map을 구한다.
3. attention map을 이미지 전체로부터 feature를 추출한 feature map에 다시 적용하여 attention based (image-level) contextual feature를 구한다.
instance appearance feature는 말그대로 instance에 기반한 feature(local feature)만 담고있고 이미지 전체에 attention map을 적용하여 구한 contextual feature는 말그대로 attention map에 기반해서 이미지 전체의 feature(global feature)를 담고있다. local & global feature를 모두 적용하기 위해 이 둘을 concatenate시키고 이를 통해 주어진 human instance에 대한 action score인 식 1-(2) 를 구한다.
<Spatial Configuration>
해당 stream에서는 human-object사이의 spatial relationship에 기반하여 action score인 식 1-(3) 을 구한다.
따라서 인풋은 human, object bounding box의 pair이고 모든 쌍에 대해서 계산을 해야한다.
임의의 (human, object) pair가 주어지면 두 bounding box영역만 1로 채운 matrix가 인풋으로 들어가고 CNN, MLP를 통해 5408개의 feature가 생성되면 여기에 x^h_inst를 concatenate시킨다.
x^h_inst도 붙이는 이유는 human, object의 공간적인 relationship에 추가적으로 human이 어떤 pose를 취하는지를 뜻하는 appearance feature(x^h_inst)를 concatenate시키는게 효과적이기 때문이라고 말한다.



