CNN, R-CNN, Object Detection, HOI 등.. 과 관련한 논문들에서 흔히 나오는 용어들을 정리한 글입니다.
<descriptor>
이미지를 비교하기 위해 동일한 방법을 통해 어떤 특징을 하나의 비교 대상으로 만드는 것을 말한다.
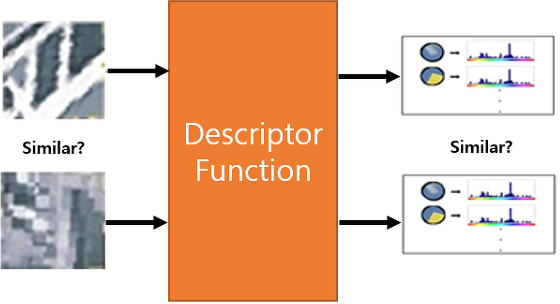
예를들어, Object Detection과 Face Detection 등에서 이용되는 HOG 알고리즘 같은 경우 이미지를 비교하기 위해
이미지의 각 pixel에서 gradient(기울기) vector를 구하고 이 vector들을 이용해 8가지 방향에 대한 히스토그램을 생성한다.
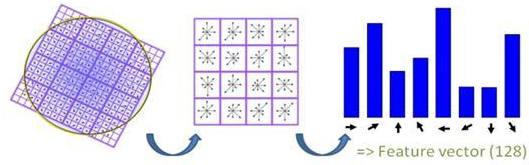
이렇게 HOG같은 경우 이미지를 비교하기 위해 기울기의 방향을 descriptor로 사용한다.
* Object Detection 문제를 해결하기 위해 SIFT, SURF, HOG와 같은 알고리즘을 이용하여 이미지에서 키포인트를 추출한 후 그 키포인트를 bounding box에 활용하는 방법이 있다.
<Region Proposal>
R-CNN과 같은 Object Detection에서 사용되는 용어이다.
일반적으로 R-CNN과 같은 메소드에서 이미지로부터 영역을 선택하기 위해 사용되는 알고리즘이다.
기존의 sliding window방식의 비효율성을 개선하기 위해 '물체가 있을법한' 영역을 빠른 속도로 찾아내는 알고리즘이다.
다양한 region proposal알고리즘이 있지만 보편적으로 selective search와 edge boxe알고리즘이
좋은 성능과 속도를 보인다.

<RoI (Region of Interest)>
이미지내에서의 관심 영역.
R-CNN에서 region proposal 알고리즘을 통해 여러 영역들을 cropping하는데 이 영역들을 RoI라고 한다.
또한 Fast R-CNN에서 각 영역들의 크기가 다른데 이를 R-CNN에서 warp하는 것이 아닌 max pooling을 이용한 방식인
Spatial Pyramid Pooling을 이용하여 같은 크기의 output이미지로 만들어 준다.
이때 이 Pooling을 RoI Pooling이라고도 한다.
RoI Pooling (설명 : https://blog.lunit.io/2017/06/01/r-cnns-tutorial/)
<Ground truth>
Supervised learning에서는 학습할때 input 데이터와 정답 output인 label을 이용하여 학습한다.
이때 신경망 모델이 예측한 값 (predicate)가 아닌 실제 정답 label을 'ground truth'라고 한다.
(ex. Object detection내에서 ground truth location : 어떤 객체의 실제 위치)
<Caption generation>
Human-object interaction에 기초하여 연구되고 있는 것 중 하나로 이미지로부터 문장을 생성하는 것을 말한다.
"Detecting and Recognizing Human-Object Interactions" 논문에서는 Human-centric recognition 이 잘 수행되면
"action-specific image retrieval (action 별로 이미지 검색)", "question answering"과 더불어
이미지로부터 문장을 생성하는 "Caption generation"에 아주 효율적으로 이용될 수 있다고 얘기한다.
<L1 loss, L2 loss>
L1 loss :
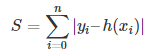
정답 label과 예측한 값의 절대값 차이를 모두 더해 loss로 정의한 것이다.
L2 loss :

정답 label과 예측한 값의 차이를 제곱한 값을 모두 더해 loss로 정의한 것이다.
수식설명 :
L2의 경우 오차의 제곱을 더하기 때문에 데이터셋에서 아웃라이어에 매우 민감하다.
따라서 L2는 모델을 fitting할때 다른 중요한 샘플들이 많이 있어도 아웃라이어 값에 더 의존적인 경향이 있다.
반면에 L1의 경우 안정적이고 아웃라이어에 영향을 덜 받는 경향이 있다.
(*아웃라이어 : 데이터 중에 다른 값들에 비해 지나치게 높거나 낮은 데이터)
<Smooth L1 loss>
수식 :
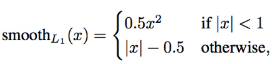
수식에서의 x는 |y-h|로 정답 label과 예측한 값의 차이라고 보면 된다.
위에서 본 L1 loss와 비슷하지만 |x| < 1인 부분(즉, 오차가 작은 부분)에서 곡선이고 외에 영역에서는 직선이다.
따라서 error의 값이 충분히 작을 경우 거의 맞는 것으로 판단하며, loss값이 빠른 속도로 줄어들게 된다.
아래 그림은 L1 loss, L2 loss, smooth L1 loss를 나타낸 것이다.
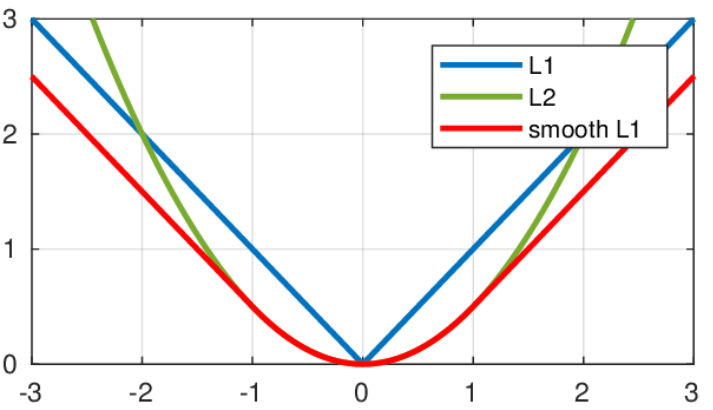
여기서 x축은 |y-h|로 label과 예측값의 차이이다.
L2 그래프를 보면 오차의 제곱이아닌 1/2(오차의 제곱)을 사용한 것을 확인할 수 있다.
<Dominant complexity(computation>
complexity를 결정하는 최대 차수
(ex. 100N^2 + 200N^4 에서 dominant complexity는 N^4이고 따라서 복잡도는 O(N^4)을 따른다.)
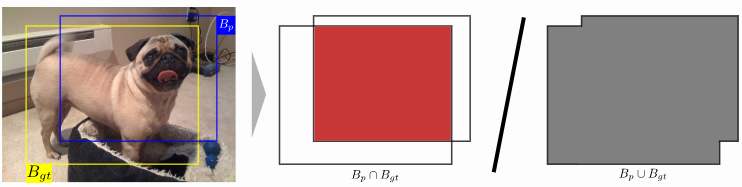
<IOU (Intersection over union)>
Object Detection에서 bounding box로 object의 위치를 나타낸다.
이때 모델이 예측한 bounding box, Bp와 실제 ground-truth bounding box, Bgt의 영역을 비교한다.
일반적으로 두 영역을 비교했을때 겹치는 넓이가 두 영역을 합친 넓이의 0.5이상일때 매치되었다고 한다.
(PASCAL VOC Challenge 에서 IoU의 threshold를 0.5로 하고있음)
수식 :
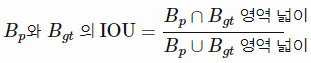
<Ablation study>
기존의 모델에 feature들을 제거해나가면서 그 feature가 성능에 얼마나 영향끼쳤던건지 확인해보는 것
여기서 feature는 모델의 구조 중 특정 network혹은 layer가 될 수 있다.
<Jittered examples>
Object detection에서 모델이 예측한 bounding box의 positive / negative 여부는 IoU로 결정한다.
R-CNN에서 IoU가 0.5보다 크면 positive라하는데 이 positive 영역들을 jittered examples라 한다.
<Non-maximum suppression (NMS)>
object detection 에서 사용되는 알고리즘으로 동작과정은 다음과 같다.
1. 동일한 클래스에 대해 검출된 bounding box들을 confidence 순서로 정렬한다.
2. 가장 confidence가 높은 bounding box와 IoU가 일정 이상인 bounding box는
동일 물체를 detect했다 판단하여 지운다. (보통 0.5이상 box들을 지운다 / 가장 confidence높은것만 남기고)
NMS 알고리즘 적용 전

NMS 알고리즘 적용 후

<OHEM (Online Hard Example Mining)>
일반적으로 Classification에서 Loss 함수로 Cross entropy를 사용한다.
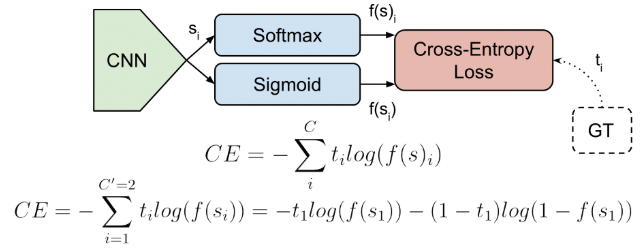
식을보면 알겠지만 Cross entropy loss는 gt값 t와 prediction값 f(s)를 곱한값으로 결정된다.
따라서 이미지상으로 볼때 easy example과 hard example이 있을텐데 이 둘에 대해서 loss가중치가 똑같다.
ex) 사람 동상이 있을때 이를 사람으로 분류할지 동상으로 분류할지 어렵다 -
이와같은 example을 hard negative example이라 한다.
Object detector의 경우 일반적으로 anchor box를 생성하고 각 anchor box마다 이처럼 classification loss를 구한다.
이때 이미지내에서 대부분의 anchor box가 background이고 몇개의 anchor box만이 object가 있는 box이다.
이렇게 이미지내에서 검출된 RoI examples들 중에서 극히 일부만 object를 포함하고 있는, positive examples이고
대부분의 examples들은 background를 포함하는 negative examples이다. 이런 문제를 "Class Imabalance"라고 한다.
이때 위처럼 모든 example에 대해서 loss가중치를 똑같이 준다면 결국 네트워크는 수천개의 background가 담긴
box위주로만 학습이 될 것이다. 이를 방지하고자 나온 개념이 OHEM이다.
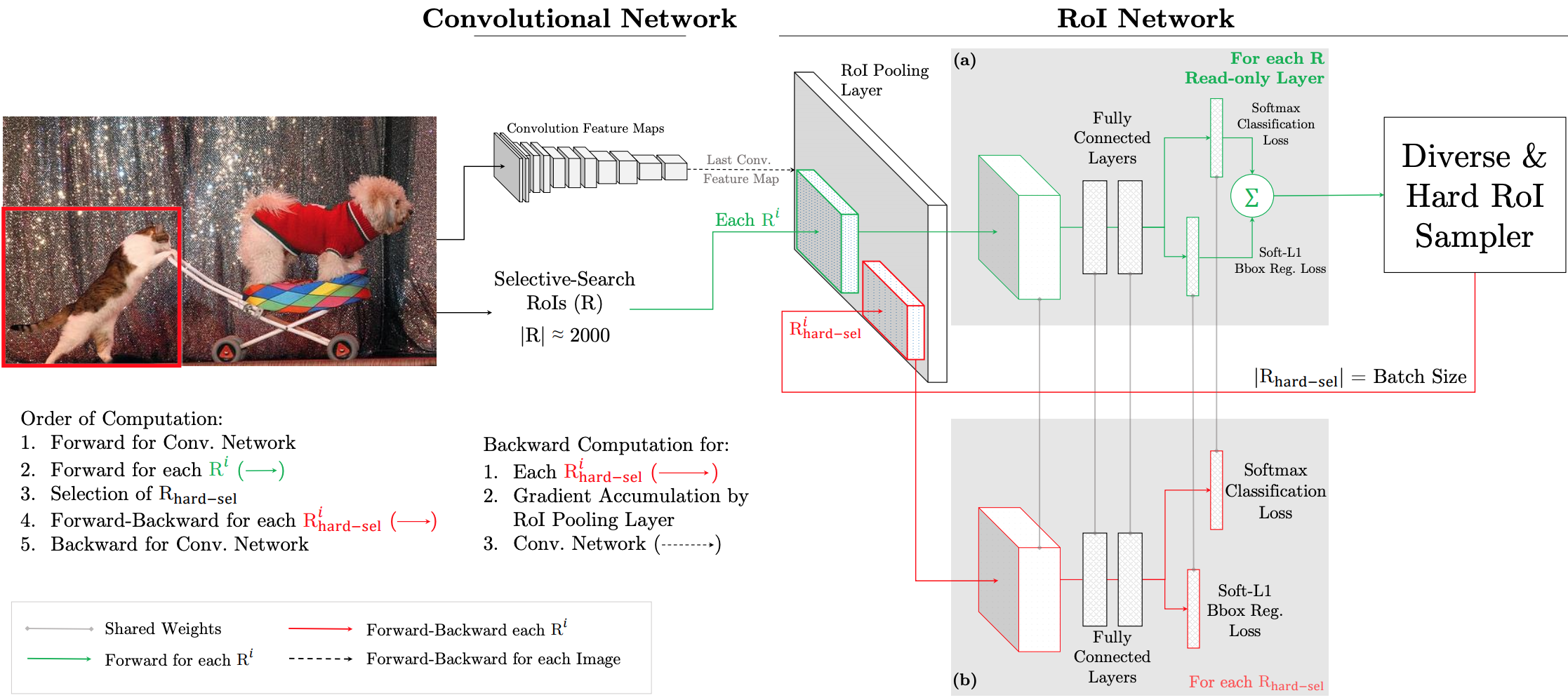
OHEM은 data에서 positive와 hard negative example로 data를 필터링하고 해당 data에 대해서만
학습을 하자는 개념이다. 따라서 Object detection에서 모든 anchor box에 대해서 classification loss를 구하지 않고
각 anchor box들을 ground truth과 비교하여 score를 계산을 한다.
이때 score가 높은데 gt값이 0이라면 obejct로 인식할뻔한 배경사진이라는 뜻이다.
따라서 이런 box들의 경우 hard negative example이라 한다.
최종적으로 이런 box들과 positive box들만 골라서 classification loss를 계산하도록 한다.
<Focal Loss>
OHEM과 비슷하게 모든 data에 대해서 loss에 같은 가중치를 주지 말자는 의도이다.
Focal Loss에서 loss function은 다음과 같다.
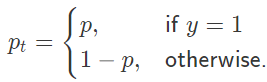
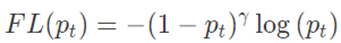
loss function을 해석해보자면
y=1일때 pt=p이므로 p가 작을수록 (1-p)가 커져서 loss가 커진다. 반대로 p가 커지면 (1-p)가 줄어서 loss가 작다.
즉, positive에 대해 잘 예측한 경우 loss를 작게주고 예측하지 못한 경우 loss를 크게준다.
y=0일때 pt=1-p이므로 FL(pt)=-p^r*log(1-p)이다. 따라서 p가 작을수록 loss가 작아지고
p가 클수록 (=hard negative example) loss가 커진다.
결국 너무쉬운 data에 대해서는 학습을 더디게하고 어려운 data에 대해서 학습을 빠르게 한다.
실제로 Focal Loss의 경우 OHEM보다 성능이 더 좋다고 한다.
<Contextual feature>
2d image에서 contextual based classification은 pixel의 주변 neighborhood 과의 relationship에 초점을 맞춘 approach를 뜻한다. 즉, 어떤 특정 pixel의 contextual feature는 주변 pixel들과의 relationship에 기반해서 추출한 feature를 뜻한다.
'인공지능 AI > 컴퓨터비전' 카테고리의 다른 글
| Semantic segmentation과 Instance segmentation의 차이 (0) | 2020.02.17 |
|---|---|
| translation invariance 설명 및 정리 (8) | 2020.02.16 |
| GAP(Global Average Pooling) vs FCN(Fully Convolutional Network) (4) | 2020.01.30 |
| 1-Stage detector와 2-Stage detector란? (1) | 2020.01.13 |
| GNN, GCN 개념정리 (4) | 2020.01.05 |



