<Introduction>
translation invariance를 설명하기 위해 먼저 Classification에 대해 살펴보자.
Classification은 Image가 주어졌을때 이 이미지가 어떤 사진인지, 어떤 Object를 대표하는지 분류하는 문제이다.
따라서 아래 그림에서과 같이 고양이의 위치가 변하여도 Classification에서는 똑같이 고양이라고 분류해야한다.

이를 "translation invariance" 라고 한다.
"CNN에서 translation invariance란 input의 위치가 달라져도 output이 동일한 값을 갖는것을 말한다"
사실 CNN 네트워크 자체는 translation equivariance(variance)하다. convolution filter로 연산을 할때 특정 feature의
위치가 바뀌면 당연히 output에서 해당 feature에 대한 연산결과의 위치도 바뀌기 때문이다. (Figure 1.)
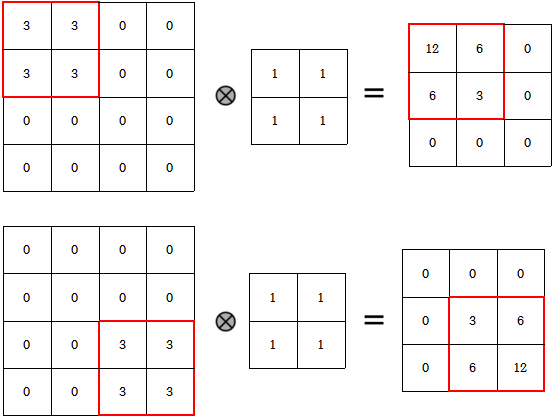
이렇듯 CNN은 translation equivariance한데 어떻게 CNN으로 이루어진 Classification이 translation invariance할까?
이는 다음의 3가지 과정을 통해 translation invariance하게 된다고 볼 수 있다.
1. Max pooling
2. CNN의 특징인 Weight sharing & Learn local features
3. Softmax를 통한 확률값 계산
<Max pooling>
먼저 max-pooling은 대표적인 small translation invariance함수이다. 예시를 통해 이를 쉽게 확인할 수 있다.
orginal image의 pixel값을 [1, 0, 0, 0]이라하자.
그리고 original image를 각각 translate시킨 A, B는 [0, 0, 0, 1], [0, 1, 0, 0]의 값을 갖고 있다.
이들을 2 x 2 max pooling시키면 모두 동일하게 output으로 1을 갖는다는 것을 알 수 있다.
이처럼 Max pooling은 k x k filter 사이즈만큼의 값들을 1개의 max값을 치환시킨다.
따라서 k x k 내에서 값들의 위치가 달라져도 모두 동일한 값을 output으로 갖게된다.
"즉, k x k 범위내에서의 translation에 대해서는 invariance하다."
<Weight sharing & Learn local features>
CNN의 두가지 특성은 다음과 같다.
1. 동일한 weight를 가진 filter를 sliding window로 연산한다. - Weight sharing
2. global이 아닌 local feature들과 연산함으로써 local feature를 학습한다. - Learn local features
즉, CNN은 k x k 사이즈의 필터를 모든 픽셀에 대하여 동일 값으로 sliding window로 연산을 진행한다.
따라서 각 필터는 image내 어떤 object의 위치와 상관없이 특정 패턴을 학습하는 것이다.
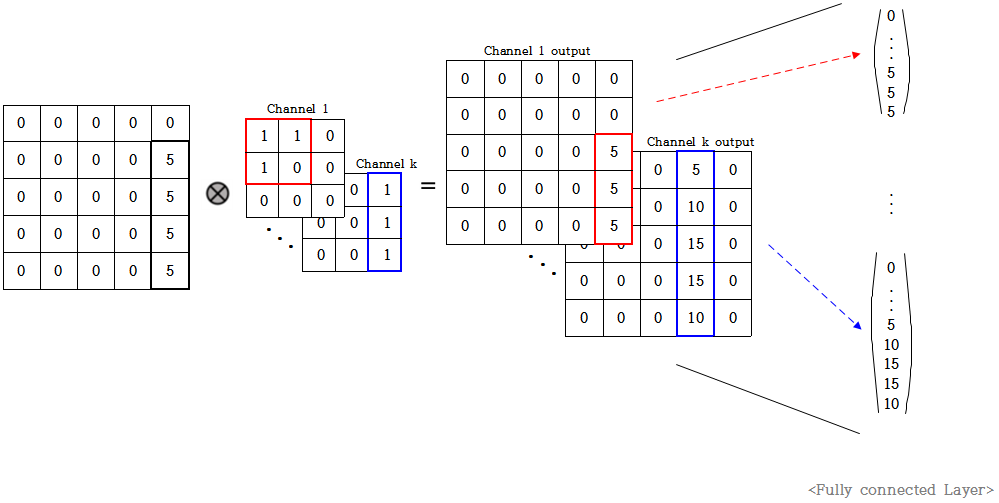
위 그림을 살펴보면 original image는 5 x 5 사이즈이고 가장 오른쪽에 길다란 어떤 object가 있음을 알 수 있다.
이 이미지에 위와같이 3 x 3 filter k개로 convolution 연산을 한다고 가정하자.
channel 1은 삼각형 모양을 한 필터이고 channel k는 original image와 같이 오른쪽에 길다란 모양을 한 필터이다.
padding을 same으로 뒀을때 convolution 연산의 결과로 위와같이 5 x 5 feature map이 k개 나온다.
이때 1번째 feature map은 삼각형 모양을 한 필터로 연산을 했으므로 그리 큰 값을 갖지 않는다.
하지만 k번째 feature map은 original image와 동일한 모양의 값을 가진 필터로 연산을 했기에 큰 값을 갖는다.
따라서 이 k개의 feature map들을 FC layer를 통해 dense하게 펼쳤을때 앞부분의 노드들은 비교적 작은 값을 갖고
마지막 뒷부분의 노드들은 큰 값을 갖는다. 그러나 여기까지도 아직은 translation equivariance하다.
FC layer의 특성상 FC 이전의 모든 network가 invariant하면 first FC도 invariant할 수 있지만
위에서 설명했듯이 CNN은 equivariance이므로 현재 전체 network도 아직은 equivariance이다.
그러나 위 그림을 보면 알 수 있듯이 각각의 노드 값의 위치가 object의 위치에 따라 달라질 수 있어서
아직은 equivariance하지만 위치가 달라져도 5 x 5 사이즈 내에서만 달라진다는것을 알 수 있다.
따라서 동일 가중치를 모든 픽셀이 공유하면서 local하게 연산하기에 FC layer에서의 output값들도
input image의 local value들의 영향을 받아 특정 사이즈 내에서만 equivariant하게 값이 바뀐다.
<Softmax를 통한 확률값 계산>
위 과정까지는 아직 translation equivariance하다. 그러나 이를 invariance하게 만들어주는 과정이 Softmax과정이다.
Classification에서는 feature map들을 FC layer와 연결하고 마지막 label개수만큼 output node를 설정하여
최종적으로 이들을 softmax를 통해 classification 결과를 결정한다. 위 예에서 output label은 10개라고 가정하자.
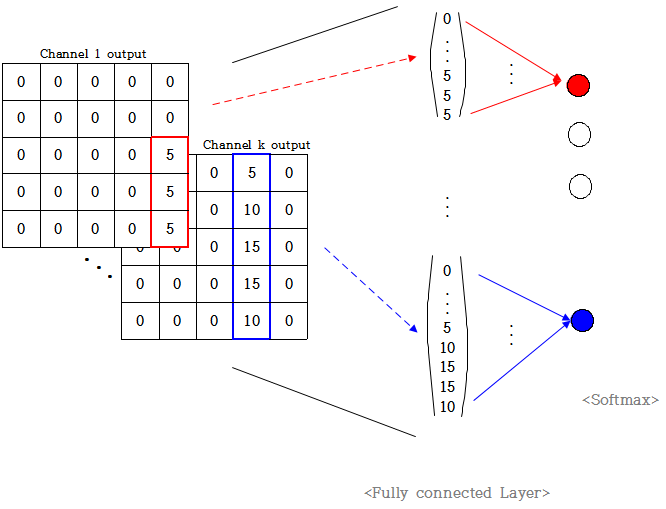
위 그림을 보면 마지막에 output label k개와 FC layer를 연결하였고 마지막에 softmax로 output값을 결정한다.
이때 각 output node가 channel개수만큼의 노드들과만 대응되도록
weight를 channel개수만큼만 1로하고 나머지는 0으로한다고 가정해보자.
즉, 위 예시에서 output node 1은 1~25 노드와 weight 1로 연결되어있고 나머지는 weight 0으로 연결됐다.
마찬가지로 output node k는 마지막 25개 노드와 weight 1로 연결되고 나머지는 weight 0으로 연결됐다.
따라서 위 예시와 같이 feature map k에 높은 값들이 많이 있으면 output node k는 높은 값을 갖는다.
최종적으로 이들을 softmax로 연산하면 결국 output으로 node k가 나오게 된다.
결국 classification으로 output k가 나오기 위해서는 feature map k에 높은 값이 많으면 되는 것이고
feature map k에 높은 값이 많으려면 channel k와 original image가 비슷한 패턴을 갖고 있어야 한다.
"즉, object의 위치와 상관없이 패턴이 동일하면 동일한 output을 갖게 된다"
<요약>
CNN자체는 translation equivariance한 네트워크이다. input value의 위치가 변함에 따라 feature map value도 변한다.
그러나 max pooling에 의한 약간의 translation invariance와 CNN 특징 + Softmax를 통한
translation invariance로 인해 Classification은 translation invariance한 성질을 갖게 된다.
'인공지능 AI > 컴퓨터비전' 카테고리의 다른 글
| Semantic segmentation과 Instance segmentation의 차이 (0) | 2020.02.17 |
|---|---|
| GAP(Global Average Pooling) vs FCN(Fully Convolutional Network) (4) | 2020.01.30 |
| 1-Stage detector와 2-Stage detector란? (1) | 2020.01.13 |
| 컴퓨터비전에서의 기본 용어 및 개념 정리 (2) | 2020.01.11 |
| GNN, GCN 개념정리 (4) | 2020.01.05 |



