<Introduction>
컴퓨터 비전에는 크게 4가지의 과제가 있다.
1. Classification
2. Object Detection
3. Image Segmentation
4. Visual relationship

이 글에서는 이 중 3. Image Segmentation에 관해 다룰 예정이다.
먼저 Image Segmentation 이전의 과제들인 Classification과 Object Detection에 대해 간단히 설명하자면
Classification은 Image가 주어졌을때 이 이미지가 어떤 사진인지, 어떤 Object를 대표하는지 분류하는 문제이다.
따라서 위 그림에서 고양이의 위치가 아래 예시와 같이 변하여도 Classification에서는 똑같이 고양이라고 분류해야한다.

이를 "translation invariance" 라고 하며 Classification은 translation invariance를 만족해야한다.
translation invariance에 대한 자세한 설명은 아래 게시글에서 확인할 수 있다.
translation invariance 설명 및 정리
translation invariance 설명 및 정리
translation invariance를 설명하기 위해 먼저 Classification에 대해 살펴보자. Classification은 Image가 주어졌을때 이 이미지가 어떤 사진인지, 어떤 Object를 대표하는지 분류하는 문제이다...
ganghee-lee.tistory.com
Object detection은 object의 분류뿐만 아니라 해당 object가 어느 위치에 있는지 bounding box를 통해 찾아야한다.
즉, localization을 수행해야하며 classification과 다르게 위치를 찾아야하므로 더이상 "translation invariance"이면 안된다.
따라서 Object detection은 "translation variance"를 만족해야한다.
그렇다면 Image segmentation은 무엇일까?
Image segmentation은 이미지의 영역을 분할해서 각 object에 맞게 합쳐주는것을 말한다.
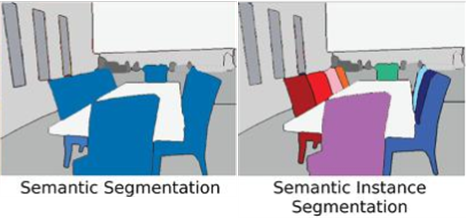
Image segmentation의 대표적인 예로는 Semantic segmentation과 Instance segmentation이 있다.
위 그림에서 보다시피 Semantic segmentation이란 Object segmentation을 하되 같은 class인 object들은
같은 영역 혹은 색으로 분할하는 것이다.
반대로 Instance segmentation은 같은 class이여도 서로 다른 instance로 구분해주는 것이다.
따라서 object가 겹쳤을때 각각의 object를 구분해주지 못하는 Semantic segmentation에서의 문제를
Instance segmentation을 통해 해결할 수 있다.
<Semantic segmentation vs Instance segmentation>
Object detection에서와 마찬가지로 Image segmentation에서 역시 object의 localization을 수행해야하기에
Image segmentation은 translation variance을 만족해야한다.
Semantic segmentation은 각 픽셀별로 어떤 class에 속하는지 label을 구해줘야 한다.
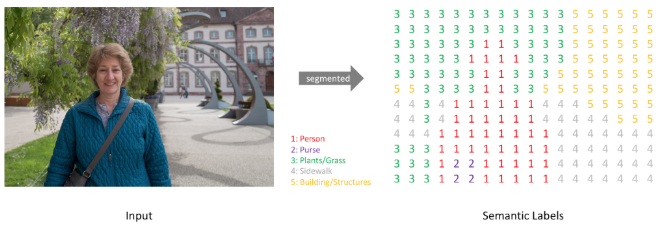
따라서 One-Hot encoding으로 각 class에 대해 class개수만큼 출력채널을 만든다.
그 후 argmax를 통해 위 이미지처럼 하나의 output을 계산한다.

이렇게 semantic segmentation은 pixel들이 각 class에 대해 binary하게 포함되는지 안되는지 여부만 따진다.
즉, 강아지 ouput channel에서는 각 pixel들에 대해 강아지에 포함되는 pixel인지 아닌지,
사람 output channel에서는 각 pixel들이 사람에 포함되는 pixel인지 아닌지, .. 0과 1로 binary하게 값을 갖는다.

따라서 위와같이 segmentation되는데 이때 같은 class의 object들에 대해 서로 구분지을수 없다는 단점이 있다.
우측하단의 차들을 보면 몇대의 차가 어떻게 겹쳐져있는지 알 수 없고 단지 저 pixel들이 차에 포함된다는 것만 알 수 있다.
반대로 Instance segmentation은 각 픽셀별로 어떤 카테고리에 속하는지 계산하는 것이 아닌
각 픽셀별로 object가 있는지 없는지 여부만 계산한다.
일반적으로 Mask R-CNN과 같은 2-stage detector에서는 먼저 object들을 bounding box를 통해
localization시킨다. 그 후 위에서 class별로 output 채널을 만든 것과 같이 localize된 RoI마다 class의 개수만큼
binary mask(instance인지 아닌지) 마스크를 씌워준다.
semantic segmantation과 다르게 이미지 사이즈 크기로 class 개수만큼 output 채널이 존재하지 않고
RoI별로 class 개수만큼 output 채널이 존재하고 동일 class더라도 서로다른 instance,
즉 RoI가 focus하는 instance부분만 value를 갖도록 한다.

요약하자면,
class label이 10개 존재하는 경우 Semantic segmentation에서는 각 pixel들이 어떤 class에 포함되는지 안되는지를 10개의 class에 대해서 각각 binary하게 계산한다.
반면, Instance segmentation은 이미 localization을 수행한 후 그 box가 focus하고 있는 instance의 pixel이 궁금한 것이므로 각 box에 대해 image segmentation을 하는데 이때 동일 class여도 서로다른 instance이면 value를 갖지 않는다.
'인공지능 AI > 컴퓨터비전' 카테고리의 다른 글
| translation invariance 설명 및 정리 (8) | 2020.02.16 |
|---|---|
| GAP(Global Average Pooling) vs FCN(Fully Convolutional Network) (4) | 2020.01.30 |
| 1-Stage detector와 2-Stage detector란? (1) | 2020.01.13 |
| 컴퓨터비전에서의 기본 용어 및 개념 정리 (2) | 2020.01.11 |
| GNN, GCN 개념정리 (4) | 2020.01.05 |



